Lexical Analysis
Lexical Analysis: Chop the program into tokens
- Input: A character stream
- Output: A token stream
Lexical analysis transforms its input (a stream of characters) from one / more source files into a stream of language-specific lexical tokens.
Lexical Analysis Tasks:
- Delete irrelevant information (whitespace, comments)
- Determine lexical token boundaries in source stream
- Transmit lexical tokens to next pass
- Deal wit ill-formed lexical tokens, recover from lexical errors.
- Transmit source coordinates (file, line number) to next pass.
Programming language objects a lexical analyzer must deal with
- Identifiers
- Reserved words or Keywords
- Literal constants: integer, real, string, etc.
- Special characters: “+”, “-“, “*”, “/” etc
- Comments
A programming language should be designed so that the lexical analyzer can determine lexical token boundaries easily
In most languages, lexical tokens are designed to be easily separated based a single left to right scan of the input stream without backup
Building Lexical Analysis
Describe the lexical structure of the language using regular expressions.
Modern parsing tools like Flexm JFlex, and ANTLR will
- Generate a NFA that recognizes the strings(regular sets) specified by the regular expressions.
- Convert the NFA into a DFA
- Implement the DFA using a table-driven algorithm.
Regular Expression
Regular expression notation is a convenient way to precisely describe the lexical tokens in a language.
The sets of strings defined by regular expressions are regular sets.
Each regular expression defines a regular set.
Notations:
- ”+” 1 or more repetitions
- “*” 0 or more repetitions
- ”[]” for denoting a set of characters
- ”()” for parenthesis
Characters may be quoted in single quotes to avoid ambiguity
Examples:
- Identifier:
[a-zA-Z][a-zA-Z0-9_]* - Digits:
[0]|([1-9][0-9])* - WhiteSpaceBlock:
[\t\r\n]+
Finite Automata
Finite automata(state machines) can be used to recognize tokens specified by a regular expression.
A finite automaton (FA) is
- A finite set of states
- A set of transitions from one state to another. Transitions depend on input characters from the vocabulary.
- A distinguished start state
- A set of final (accepting) states.
If the FA has a unique transition for every (state, inout character) pair then it is a deterministic FA(DFA)
The input to the DFA is the next input character to the lexical analyzer.
The main state of the DFA uses the character to classify the type of possible token, e.g., identifier, number, special character, whitespace.
For lexical tokens that can consist of more than one character, the main state transitions to a sub-state that deals with accumulating one type of lexical token, e.g. identifier, number
Once a complete token has been recognized by the DFA, it is packaged into a lexical token data structure and sent onward to syntax analysis
Each sub-state consumes the characters in its lexical token and returns to the main state to deal with the character immediately after its token.
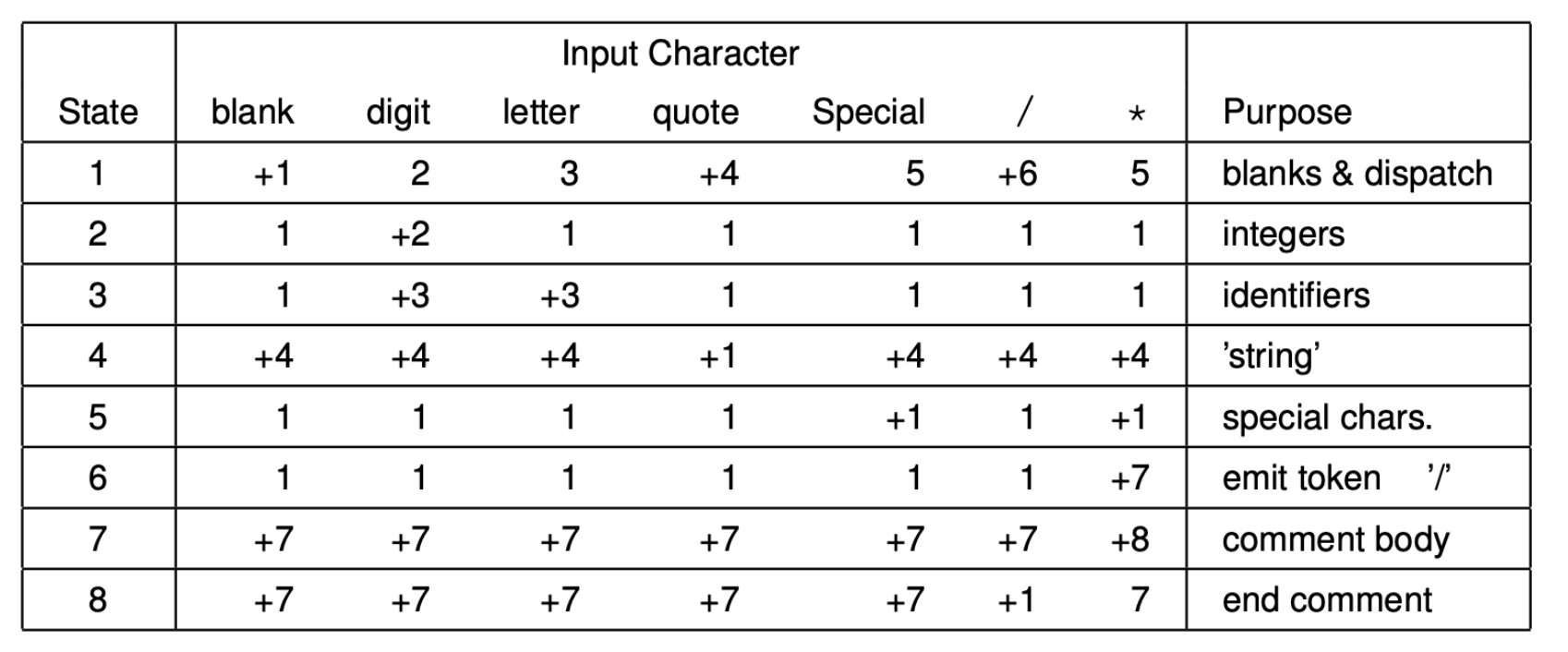
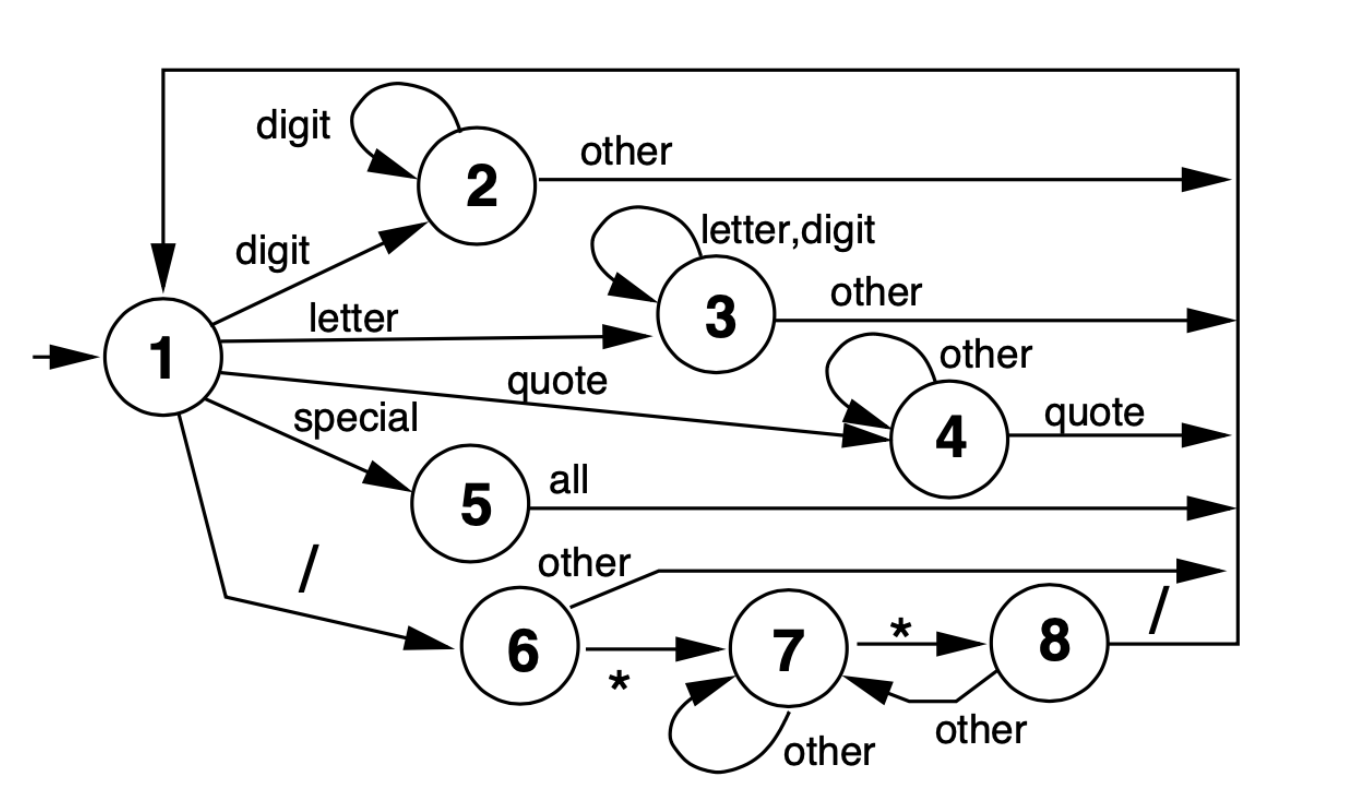
Table Driven DFA Scanner Example
Language with whitespace, integers, identifiers, string, special characters, C style comments.
Make lexical analysis decisions with 1 character look ahead.
Advance in input, save start of long tokens.
Save input pointer on entry to each state. If appropriate emit accumulated token on return to state1
Notation:
- N: Change to state N
- +N: Advance input pointer and change to state N
| Lexical Table | Lexical DFA |
 |
 |
Example:
- Based on the lexical table & lexical dfa above trace the process of string “a123”
| State | Input | Transition |
| 1 | a | 3 |
| 3 | a | +3 |
| 3 | 1 | +3 |
| 3 | 2 | +3 |
| 3 | 3 | +3 |
| 3 | 1 | |
| 1 |