Syntax Analysis
Syntax Analysis: Parse the tokens into a parse tree
- Input: A token stream
- Output: A parse tree of the program
The syntax of a language defines the sequences of language tokens that form legal sentences in the language.
Examples:
X = Y * Z + W / XOKX = * Y Z + / W XErrorfor(i = 0; i < N; i = i+1)OKfor(;;;)OKfor(i 0;;)Error
Syntax analysis is the process of analyzing a sequence of lexical tokens to determine if they are a legal sentence in some given language.
Syntax analysis is based on a formal definition of the source language.
Tasks:
- Analyze a sequence of lexical tokens to determine its syntactic structure
- Verify that this syntactic structure corresponds to a legal sentence in the language being processed.
- Transform the token stream into some intermediate form(a parse tree, or an abstract syntax tree) that is suitable for subsequence processing
- Handle syntax errors in the token stream
- Maintain source program coordinates for use by subsequent passes
Top Down v.s. Bottom Up Parsing
Top Down:
- Start with the start symbol for the language
- Attempt to find a sequence of production rules that transforms the start symbol into a given sequence of input tokens
- Conceptually it builds the parse tree from the root to the leaves.
- A top down parse is called a derivation
- Recursive Descent and LL(k) are top down parsing techniques.
Bottom Up:
- Start with a sequence of input tokens
- Attempt to find a sequence of production rules that reduces the entire sequence of terminal symbols to the start symbol
- Conceptually it builds the parse tree from the leaves to the root.
- A bottom up parse is called a reduction, or a reverse derivation.
- LR(k), SLR(k) and LALR(k) are bottom up parsing techniques.
Context Free Grammar
| Terminologies | Notations |
 |
 |
For the language definition:
S -> A B
A -> a A $|$ a
B -> B b $|$ b
- Non terminals: N = {S, A, B}
- Terminals: $\Sigma$ = {a, b}
- Goal Symbols: S
- Productions: P = {S -> AB, A -> a A, A -> a, B -> B b, B -> b}
Informal Definitions
-
The productions in a grammar are a set of rules (in some notation) that define the sequences of terminal symbols that make up legal sentences in the language defined by the grammar
-
A grammar is unambiguous is there is exactly one sequence of rules for forming each legal sentence in the language.
-
A grammar is context-free (CF) if every rule can be applied completely independent of the surrounding context.
-
A language is deterministic if it is always possible to determine which rule to apply next when parsing every sentence in the language.
Table-Driven Parsing
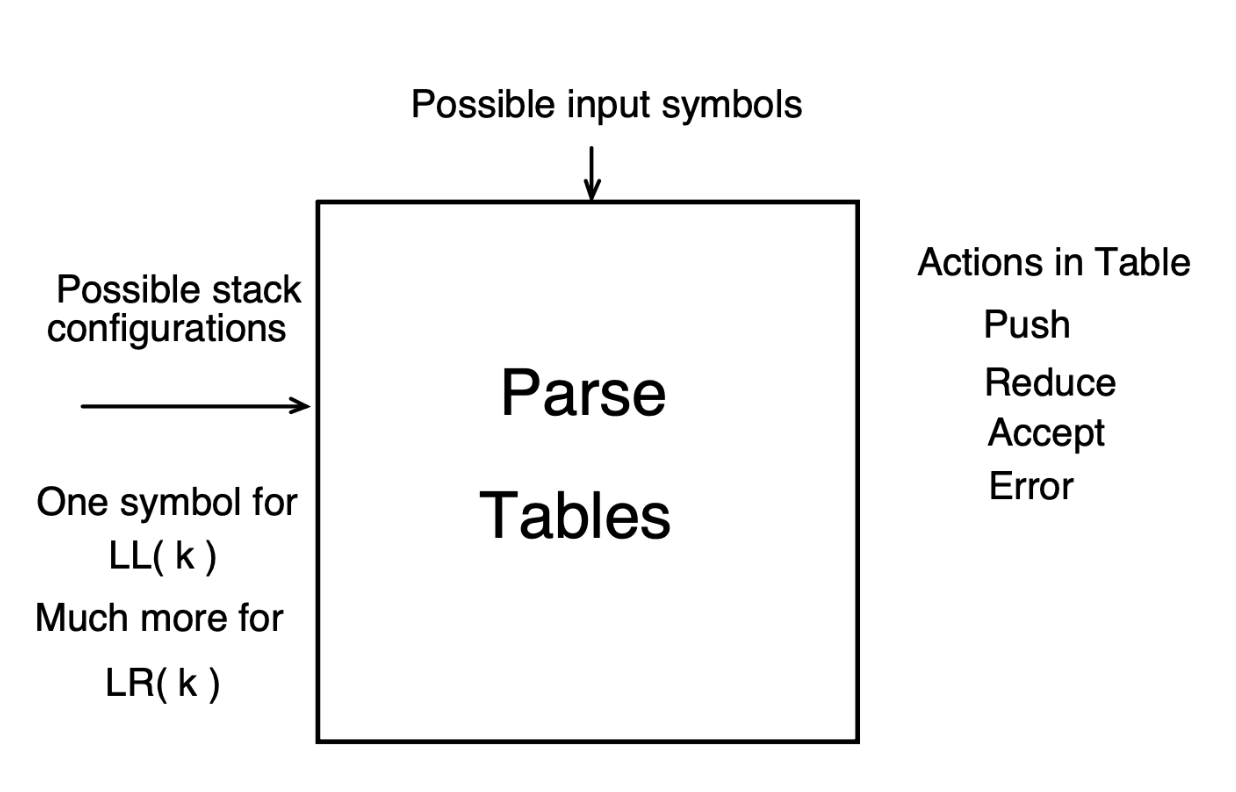
-
Conceptually a table for each parser state. Allow multiple actions per state so tables can be merged to one table for all parser states.
-
Final state is accepting or rejecting
-
Top Down - Stack represents what we expect to see
-
Bottom Up - Stack represents what we have seen so far
-
Recursive Descent: Top down parsing technique with the potential for backtracking. Recursive descent parser are usually written as a collection of interacting recursive functions.
-
LL(1): Table-driven top down parsing. Deterministic push down automaton (DPDA)
-
LR(1): Table-driven bottom up parsing. The parser uses a Shift/Reduce algorithm to record the state of its reduction.
- SLR(1), LALR(1) are practical versions of LR(1)
Top Down Parsing
Top Down parser are predictive parsers. Parse stack represents what the parser expects to see. As the parser encounters token that it expected to see, the parse stack get modified to record this fact.
If the top item in the parser stack is a non terminal symbol A then a top down parser must select one of the rules defining A as its next target.
LL(1) Parsing
LL(1) is a Top Down parsing technique. Scans input from the Left producing a Leftmost derivation.
LL(1) parser in controlled by the one incoming token, and the top item in the parse stack.
The parse stack represents what the parser expects to see. As the parser encounters a token that it expected to see, the parse stack gets modified to record this fact.
Example: Given the grammar written down the derivation of a a a b b
-
S -> A B
-
A -> a A $|$ a
-
B -> B b $|$ b
Parse Tree
1
2
3
4
5
6
7
8
9
S
/ \
A B
/\ /\
a A B b
/\ |
a A b
\
a
| Production Rule | Derivation |
| S -> A B | AB |
| A -> a A | a A B |
| A -> a A | a a A B |
| A -> a | a a a B |
| B -> B b | a a a B b |
| B -> b | a a a b b |
LL(1) - Predict Sets
The LL(1) predict sets are the decision mechanism that is used to select among various alternatives for rewriting a nonterminal symbol.
Predict set: given a nonterminal A with several alternative rules A -> $\alpha_1 |$ $\alpha_2 |$ … $| \alpha_n$
-
The Predict set for rule A -> $\alpha_i$ is:
Rule Condition Predict(A -> $\alpha_i$) = First($\alpha_i$) if $\alpha_i$ is not nullable Predict(A -> $\alpha_i$) = First($\alpha_i$) $\cup$ Follow(A) if $\alpha_i$ is nullable
For each non-terminal in the grammar, the Predict sets for the definitions of the nonterminal must be disjoint for the language to be LL(1).
LL(1) parsers must make a parsing decision at the beginning of each rule (i.e., select which $\alpha_i$ to continue with)
If inToken is the next incoming lexical token, then the parser searches for this token in the Predict sets for the rules that define A
- if inToken is in Predict(A -> $\alpha$) then the rule A -> $\alpha$ should be applied
- if inToken is not in any of the Predict sets then a syntax error is detected.
- inToken cannot occur in more than one Predict set for A in a correctly constructed LL(1) parser
Nullability - Deriving the Empty String
Nullable: $\alpha$ is nullable iff $\alpha$ can derive empty string $\lambda$
Nullability is a significant issue for the construction of parsers. When the string $\alpha$ actually produces $\lambda$ then it provides no information that the parser can use to make a parsing decision
A grammar can be processed to determine which non terminal symbols can potentially produce $\lambda$
Example:
-
A -> B C D
-
B -> $\lambda$
-
C -> B $|$ c
-
D -> B C $|$ d
Production Rule Derivation A -> B C D B C D B -> $\lambda$ C D C -> B B D B -> $\lambda$ D D -> B C B C B -> $\lambda$ C C -> B B B -> $\lambda$ $\lambda$
First Sets
First($\alpha$): the set of terminal symbols that can occur at the beginning of strings derived from $\alpha$
First Sets can be defined recursively:
| Rule | First set | Condition |
| First(c $\beta$) | {c} | c is a terminal |
| First($\lambda$) | {} | $\lambda$ cannot derive any symbol |
| First(B $\gamma$) | First(B) | if B is not nullable |
| First(B $\gamma$) | First(B) $\cup$ First($\gamma$) | if B is nullable |
Example:
- A -> B C c $|$ e D B
- B -> $\lambda$ $|$ b C D E
- C -> D a B $|$ c a
- D -> $\lambda$ $|$ d D
- E -> e A f $|$ c
| Non-Terminal | Derivation | First Set | Explanation | Result Set |
| A | B C c | First(B) $\cup$ First(C c) | B is nullable thus the first set of C c should also be included | {a, b, c, d} |
| A | e D B | {e} | e is already a terminal | {a, b, c, d, e} |
| B | $\lambda$ | {} | The first set of $\lambda$ is empty set | {} |
| B | b C D E | {b} | The b is already a terminal | {b} |
| C | D a B | First{D} $\cup$ First(a B) | D is nullable thus the first set of a B should also be included | {a, d} |
| C | c a | {c} | c is already a terminal | {a, c, d} |
| D | $\lambda$ | {} | The first set of $\lambda$ is empty | {} |
| D | d D | {d} | d is already a terminal | {d} |
| E | e A f | {e} | e is already a terminal | {e} |
| E | c | {c} | c is already a terminal | {c, e} |
Follow Sets
Follow(A): the set of terminal symbols that can occur immediately follow a non-terminal symbol A Example:
- A -> B C c $|$ e D B
- B -> $\lambda$ $|$ b C D E
- C -> D a B $|$ c a
- D -> $\lambda$ $|$ d D
- E -> e A f $|$ c
| Non-Terminal | Occurrence | Follow Set | Explanation | Result Set |
| A | e A f | {f} | f can immediately follow A | {f} |
| A | {$} | A is the top rule the end file can follow A | {f, $} | |
| B | B C c | First(C) | The non terminal C is after B, thus anything in the first set of C can appear in the follow set of B | {a, c, d} |
| B | e D B | Follow(A) | The B appears as the last symbol of one of A’s rules thus whatever follows A can appear in the follow set of B | {a, c, d, f, $} |
| B | D a B | Follow(C) | The B appears as the last symbol of one of C’s rules thus whatever follows C can appear in the follow set of B | {a, c, d, e, f, $} |
| C | B C c | {c} | c is the terminal after C | {c} |
| C | b C D E | First(D) | The non terminal D is after C, thus anything in the first set of D can appear in the follow set of C | {c,d} |
| C | b C D E | First(E) | The D is nullable thus anything in the first set of E can follow after C | {c, d, e} |
| D | e D B | First(B) | The non terminal B is after D, thus anything in the first set of B can appear in the follow set of D | {b} |
| D | e D B | Follow(A) | The B is nullable thus anything follow A should also include in the follow set of D | {b, f, $} |
| D | b c D E | First(E) | Thr non terminal E is after D, thus anything in the first set of E can appear in the follow set of D | {b, c, e, f, $} |
| D | D a B | {a} | a is terminal | {a, b, c, e, f, $} |
| D | d D | {} | {a, b, c, e, f, $} | |
| E | b c D E | follow(B) | The E appears as the last symbol of ibe if B’s rules thus whatever follows B can appear in the follow set of E | {a, c, d, e, f, $} |
LL Parsing Example
Grammar:
$S \rightarrow d S A | b A c$
$A \rightarrow d A | c$
Parse Table:
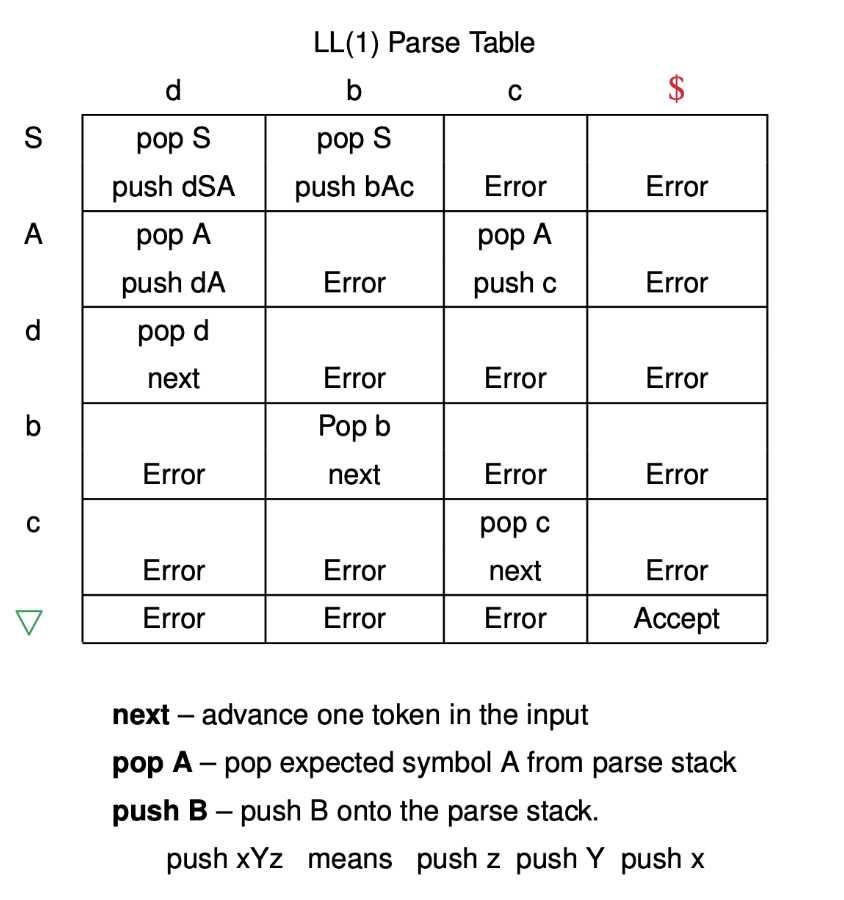
Input Tokens: d b c c d c $
| Parse Stack | Input | Action |
| S$\nabla$ | d | pop S; push dSA |
| d S A$\nabla$ | d | pop d; next |
| S A$\nabla$ | b | pop S; push bAc |
| b A c A$\nabla$ | b | pop b; next |
| A c A$\nabla$ | c | pop A; push c |
| c c A$\nabla$ | c | pop c; next |
| c A$\nabla$ | c | pop c; next |
| A$\nabla$ | d | pop A; push dA |
| d A$\nabla$ | d | pop d; next |
| A$\nabla$ | c | pop A; push c |
| c$\nabla$ | c | pop c; next |
| $\nabla$ | $ | Accept |
Issue for Top Down Parsers
Grammar rules that have a common prefix.
A $\rightarrow$ B C D x Y z
A $\rightarrow$ B C D w U v
The grammar must be rewritten for LL(k) parsing:
A $\rightarrow$ Ahead Atail
Ahead $\rightarrow$ B C D
Atail $\rightarrow$ x Y z $|$ w U v
Left recursive grammar rule, example: A -> A B C
would cause a top parser to infinitely search for an A. The grammar must be modified to remove all left recursive rules.
Remove Left Recursion
Usually left recursion can be removed by introducing new non-terminal symbols and factoring the rules so that the revised rules satisfy LL(1) property
| old rule | new rule |
| E $\rightarrow$ E + T $| T$ | E $\rightarrow$ T Etail |
| Etail $\rightarrow$ + T Etail | |
| $\lambda$ | |
| T $\rightarrow$ T * P $|$ P | T $\rightarrow$ P Ttail |
| Ttail $\rightarrow$ * P Tail | |
| $\lambda$ | |
| P $\rightarrow$ ID | P $\rightarrow$ ID |
Fix predict set conflicts
The predict sets for each non-terminal in the grammar must be disjoint for the grammar to be LL(1).
Usually non disjoint predict sets can be fixed by introducing extra non-terminal symbols to give the parser more context
| Production Rule | Predict set | Production Rule | Predict set | Production Rule | Predict Set |
| S $\rightarrow$ a B | {a} | S $\rightarrow$ a E | {a} | S $\rightarrow$ a E | {a} |
| $\rightarrow$ a c a | {a} | $\rightarrow$ d | {d} | $\rightarrow$ d | {d} |
| $\rightarrow$ d | {d} | E $\rightarrow$ B | {b, c} | E $\rightarrow$ b c | {b} |
| $\rightarrow$ c a | {c} | $\rightarrow$ c F | {c} | ||
| B $\rightarrow$ b c | {b} | B $\rightarrow$ b c | {b} | F $\rightarrow$ b | {b} |
| $\rightarrow$ c b | {c} | $\rightarrow$ c b | {c} | $\rightarrow$ a | {a} |
LL Parsing Example 2
Example:
- A -> B C c $|$ e D B
- B -> $\lambda$ $|$ b C D E
- C -> D a B $|$ c a
- D -> $\lambda$ $|$ d D
- E -> e A f $|$ c
| Non-Terminal | First Set | Follow Set |
| A | {a, b, c, d, e} | {f, $} |
| B | {b} | {a, c, d, e, f, $} |
| C | {a, c, d} | {c, d, e} |
| D | {d} | {a, b, c, e, f, $} |
| E | {c,e} | {a, c, d, e, f, $} |
| Production Rule | Derivation | Predict Set |
| A $\rightarrow$ B C c | First(B) $\cup$ First(C c) // B is nullable | {a, b, c, d} |
| $\rightarrow$ e D B | {e} | {e} |
| B $\rightarrow \lambda$ | Follow(B) | {a,c,d,e,f,$} |
| $\rightarrow$ b C D E | {b} | {b} |
| C $\rightarrow$ D a B | First(D) $\cup$ First(a B) // D is nullable | {a, d} |
| $\rightarrow$ c a | {c} | {c} |
| D $\rightarrow \lambda$ | Follow(D) | {a, b, c, e, f $} |
| $\rightarrow$ d D | {d} | {d} |
| E $\rightarrow$ e A f | {e} | {e} |
| $\rightarrow$ c | {c} | {c} |
Parse Table Rule to form the parse table
-
When the input is in the predict set and the rule does not start with terminal, replace with entire rule
-
When the input is in the predict set and the rule starts with terminal, replace with rule after terminal and advance input
-
When the input matches to the empty, pop it
-
The terminal and terminal will pop each other and advance input
| a | b | c | d | e | f | $ | |
| A | Replace(BCc) | Replace(BCc) | Replace(BCc) | Replace(BCc) | Replace(DB); Next | ||
| B | Pop | Replace(CDE);Next | Pop | Pop | Pop | Pop | |
| C | Replace(DaB) | Replace(a); Next | Replace(DaB) | ||||
| D | Pop | Pop | Pop | Replace(D);Next | Pop | Pop | |
| E | Pop;Next | Replace(Af);Next | |||||
| $\nabla$ | Accept | ||||||
| a | Pop; Next | ||||||
| c | Pop; Next | ||||||
| f | Pop; Next |
Parse “badeefcac$”
| Stack | Input | Table | Rule | Action |
| A$\nabla$ | b | A,b | 1 | Replace(B C c) |
| B C c$\nabla$ | b | B,b | 4 | Replace(C D E);Next |
| C D E C c$\nabla$ | a | C,a | 5 | Replace(D a B) |
| D a B D E C c$\nabla$ | a | D,a | 7 | Pop |
| a B D E C c$\nabla$ | a | a,a | Pop;Next | |
| B D E C c$\nabla$ | d | B,d | 3 | Pop |
| D E C c$\nabla$ | d | D,d | 8 | Replace(D);Next |
| D E C c$\nabla$ | e | D,e | 7 | Pop |
| E C c$\nabla$ | e | E,e | 9 | Replace(A f); Next |
| A f C c$\nabla$ | e | A,e | 2 | Replace(D B);Next |
| D B f C c$\nabla$ | f | D,f | 7 | Pop |
| B f C c$\nabla$ | f | B,f | 3 | Pop |
| f C c$\nabla$ | f | f,f | Pop; Next | |
| C c$\nabla$ | c | C,c | 6 | Replace(a);Next |
| a c$\nabla$ | a | a,a | Pop;Next | |
| c$\nabla$ | c | c,c | Pop;Next | |
| $\nabla$ | $ | $\nabla$,$ | Accept |
Recursive Descent Parsing
Basic Concept: Construct a mutually recursive set of functions that act as a parser for the language. Typically, each function corresponds to one rule in a grammar. Recursive Descent parsers can make parsing decisions anywhere in a rule not just at the start.
Usually easy to write, convenient for semantic analysis.
Backtracking is possible if each function is written to fail cleanly(i.e. without any side effects) if its recognition fails.
Can implement k token lookahead selectively i.e only where it is necessary to solve a particular problem.
Recursive descent is a good choice for languages with difficult or complicated syntax, e.g C++, Java, etc.
Recursive Descent Example Grammar
-
expression $\rightarrow$ term moreExpression
-
moreExpression $\rightarrow$ ‘+’ term moreExpression $|$ ‘-‘ term moreExpression $|$ $\lambda$
-
term $\rightarrow$ factor moreTerm
-
moreTerm $\rightarrow$ ‘*’ factor moreTerm $|$ ‘/’ factor moreTerm $|$ $\lambda$
-
factor $\rightarrow$ primary $|$ ‘-‘ primary
-
primary $\rightarrow$ variable $|$ constant $|$ ‘(‘ expression ‘)’
Shift Reduce Parsing - Bottom UP LR(k)
Parser Actions
- Shift: Next input symbol is pushed onto the stack
- Reduce: A sequence of symbols (the handle) starting at the top of the stack is reduced using a production
- Accept: A successful end of parse
- Error: Call recovery routine to handle syntax error
Choice of actions is based on the contents of the stack and the next k input tokens (k-symbol lookahead).
A handle is the right hand side (RHS) of some rule in the grammar. Bottom up parsing allows more than one rule to have the same RHS iff the rules can be distinguished using the left context and k-symbol lookahead.
Issue: efficiently detecting when a handle is present on top of the parse stack.
Issue: Deciding which reduction to perform.
LR(k) Parsing
The contents of the parser stack (left context) represents a string from which the past input can be derived.
Inputs are stacked until the top elements in the stack (the handle) are a complete alternative (RHS) for some rule.
When a handle is recognized, a reduction is performed and the handle on the stack is replaced by the nonterminal symbol (LHS) of the applicable rule.
Initial parser stack is $\nabla$ and parsing continues until the stack contains S $\nabla$ and the next input is $.
At each stage the top elements in the stack represent the initial portion of one or more alternative rules.
The next input symbol may narrow the number of possible alternatives. If the number of alternatives is narrowed to zero, a syntax error has occurred.
Finally, an input symbol is stacked that completes one or more alternative. If there is more than one alternative, the language is not LR(0).
At this point the next k input symbols must provide enough information to distinguish among the alternatives. If it doesn’t the language isn’t LR(k).
For LR(k) we do not need to know which alternative to choose until we reach the end of a rule. Then the next k input symbols must be sufficient to decide if a reduction can be performed.
Parsing decisions can be made later in an LR(k) parser than in an LL(k) parser. This is the reason that L(LL(1)) $\in$ L(LR(1))
In contrast, for LL(k) we had to know at the start of an alternative, given k input symbols which alternative to choose.
LR(k) parsers effectively perform a rightmost derivation in reverse.
For the grammar: S $\rightarrow$ A B A $\rightarrow$ a A | a B $\rightarrow$ B b | b
| Rightmost derivation of a a a b b | Rightmost derivation in reverse |
| S | a a a b b |
| A B | a a A b b |
| A B b | a A b b |
| A b b | A b b |
| a A b b | A B b |
| a a A b b | A B |
| a a a b b | S |
LR Parsing Example
Grammar:
| Rule | Grammar |
| 1 | L$\rightarrow$ L, E |
| 2 | $\rightarrow E$ |
| 3 | E$\rightarrow$ a |
| 4 | $\rightarrow b$ |
Parse Table:
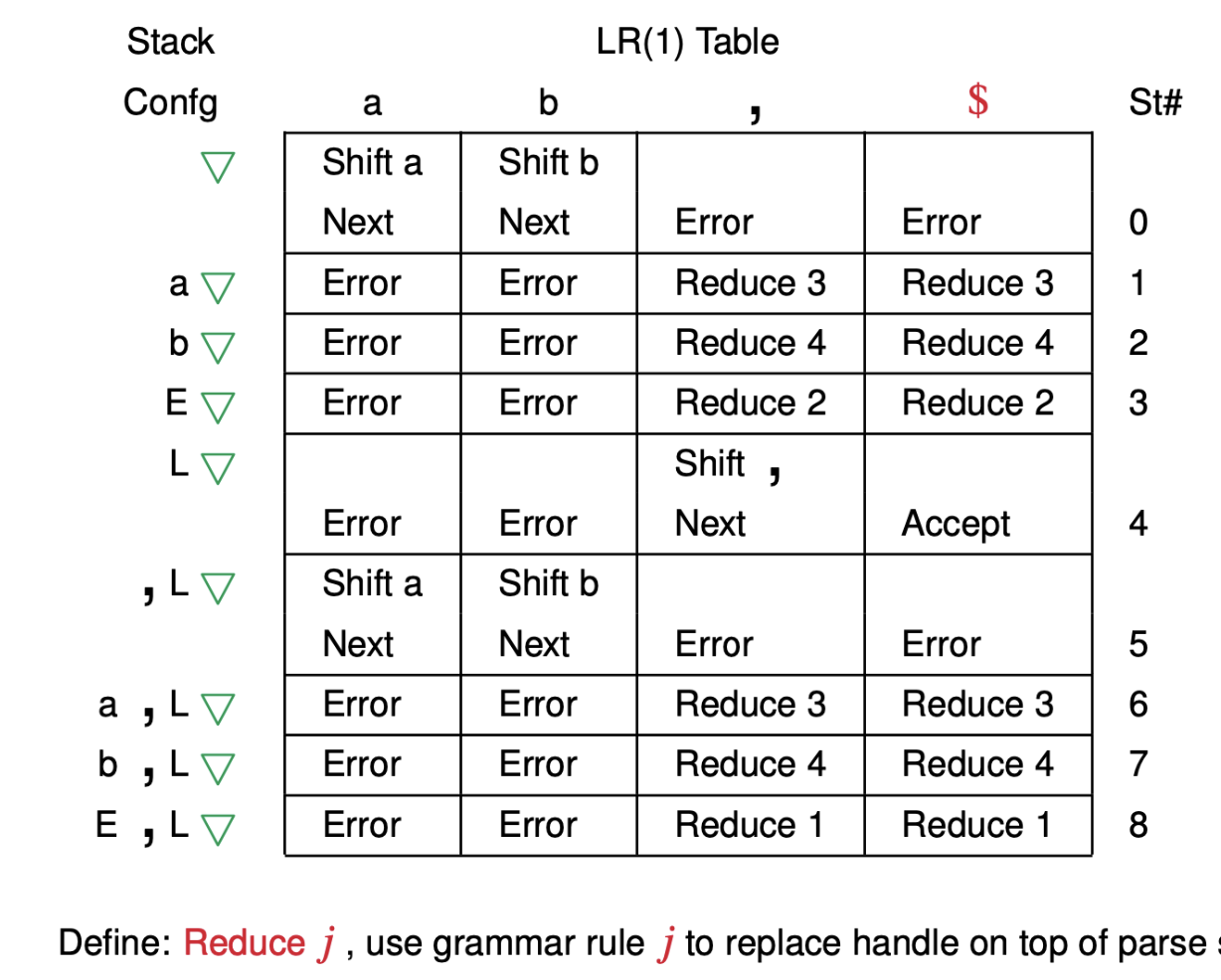
Input Tokens: a, b $
| Stack | State | Input | Action |
| $\nabla$ | $\nabla$ | a | Shift a, Next |
| a$\nabla$ | 1$\nabla$ | , | Reduce with rule 3 |
| E$\nabla$ | 3$\nabla$ | , | Reduce with rule 2 |
| L$\nabla$ | 4$\nabla$ | , | Shift , Next |
| , L$\nabla$ | 5 4$\nabla$ | b | Shift b, Next |
| b , L$\nabla$ | 7 5 4 $\nabla$ | $ | Reduce with rule 4 |
| E , L$\nabla$ | 8 5 4 $\nabla$ | $ | Reduce with rule 1 |
| L$\nabla$ | 4 $\nabla$ | $ | Accept |