Pointer Analysis Basics: Aliases
- Two variables are aliases if:
- They reference the same memory location
- More useful:
- Prove variables reference different location
- E.g.
1 2 3 4 5
int x, y; int *p = &x; int *q = &y; int *r = p; int **s = &q;
- Alias Sets:
- {x, *p. *r}
- {y, *q, **s}
- {q, *s}
- Alias Sets:
The Pointer Alias analysis Problem
- Decide for every pair of pointers at every program point
- Do they point to the same memory location?
- Correctness:
- Report all pairs of pointers which do/may alias
- Ambiguous:
- Two pointers which may or may not alias
- Accuracy/Precision:
- How few pairs of pointers are reported while remaining correct
- i.e., reduce ambiguity to improve accuracy
Pointer Analysis: Design Options
- Representation
- Heap Modeling
- Aggregate modeling
- Flow sensitivity
- Context sensitivity
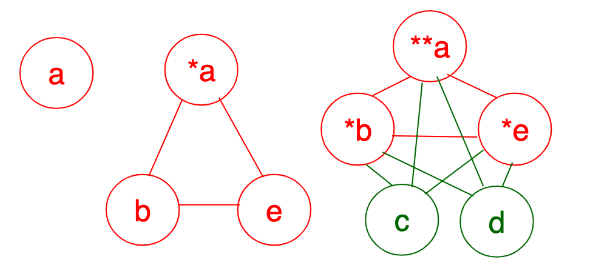
Alias Representation
- Track pointer alias
- More Precise, Less efficient
- {*a, b}, {*a, e}, {b, e}, {*a, c}, {*a, d}
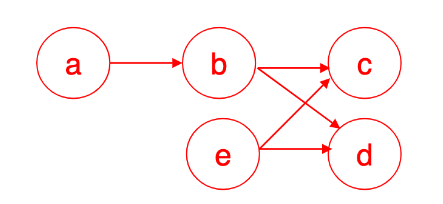
- Track points-to info
- Less Precise, More Efficient
- {a, b}, {b, c}, {b, d}, {e, c}, {e, d}
Heap Modeling Options
- Heap merged
- i.e. “no heap modeling”
- Allocation sit (any call to malloc/calloc)
- Consider each to be a unique location
- Does not differentiate between multiple objects allocated by the same allocation site
- Shape Analysis
- Recognize linked lists, trees, DAGs, etc
Aggregate Modeling Options
- Arrays
- Elements are treated as individual locations
- Treat entire array as a single location

- Treat first element separate from others
- Elements are treated as individual locations
- Structures
- Elements are treated as individual locations (Field sensitive)
- Treat entire structure as a single location

- Elements are treated as individual locations (Field sensitive)
Flow Sensitivity Options
- Flow Insensitive
- The order of statements does not matter
- Result of analysis is the same regardless of statement order
- Uses a single global state to store results as they are computed
- Not very accurate
- The order of statements does not matter
- Flow Sensitive
- The order of the statements matter
- Need a control flow graph
- Must store results for each program point
- Improve accuracy
- Path Sensitive
- Each path in a control flow graph is considered
1
2
3
4
5
6
7
8
9
S1: a = malloc();
S2: b = malloc();
S3: a = b;
S4: a = malloc();
S5: if(c)
a = b;
S6: if(!c)
a = malloc();
S7: ... = *a;
| Option | Result | Explanation |
| Flow Insensitive | {heapS1, heapS2, heapS4, heapS6} | Order does not matter, union of all possibilities |
| Flow Sensitive | {heapS2, heapS4, heapS6} | In order, does not aware exclusive |
| Path Sensitive | S2, S6 | In order, aware exclusive |
Context Sensitivity Options
- Context insensitive/sensitive
- whether to consider different calling contexts
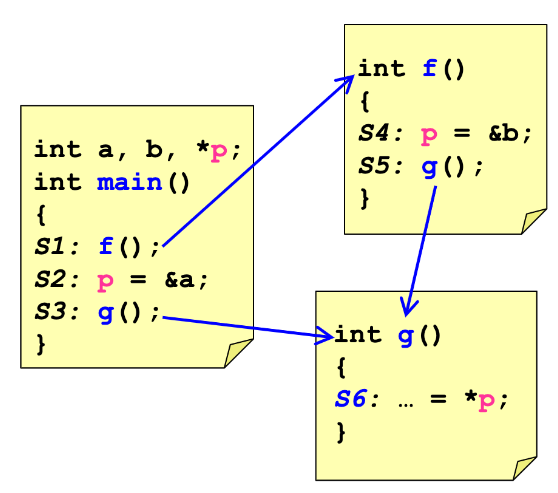 Consider the context of p at S6
Consider the context of p at S6
| Option | Result | Explanation |
| Context Insensitive | {a, b} | Union all the possibilities |
| Context Sensitive | Called from S3:{a} Called from S5:{b} |
Consider each individual path |
Address Taken Algorithm
- Basic, fast, ultra-conservative algorithm
- Flow-insensitive, context-insensitive
- Algorithm
- Generate the set of all variables whose addresses are assigned to another variable
- Assume that any pointer can potentially point to any variable in that set
-
Complexity: O(n) - linear in size of program
- Accuracy: Very imprecise
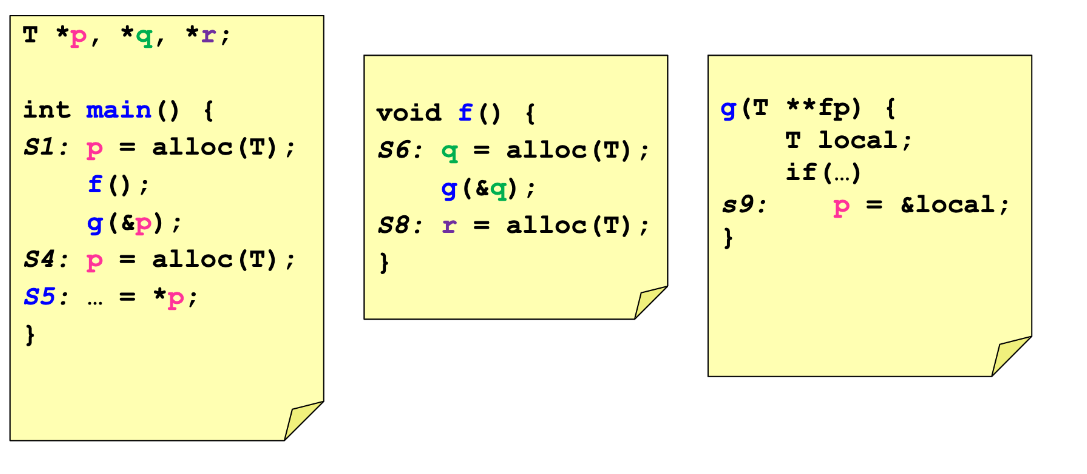
$P_{s5}$ = {$heapS_1, heapS_4, heapS_6, p, q, local$}
Andersen’s Algorithm
- Flow-insensitive, context-insensitive
- Representation:
- One points-to graph for entire program
- Each node represents exactly one location
-
For each statement, build the points-to graph:
Assignment Edge y = &xy points to x y = xif x points to w
then y points to w*y = xif y points to z and x points to w
then z points to wy = *xif x points to z and z points to w
then y points to w -
Iterate until graph no longer changes
- Worst case complexity: O($n^3$), where n = program size
|
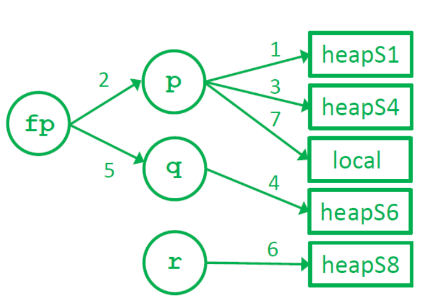 |
$P_{s5}$ = {$heapS_1, heapS_4, local$}
Steensgaard’s Algorithm
- Flow-insensitive, context-insensitive
- Representation
- A compact points-to graph for entire program
- Each node can represent multiple locations
- But can only point to one other node
- i.e. Every node has a fan-out of 1 or 0
- A compact points-to graph for entire program
- union0find data structure implements fan-out
- unioning while finding eliminates need to iterate
-
Worst case complexity: O(n)
- Precision: Less precise than Andersen’s
|
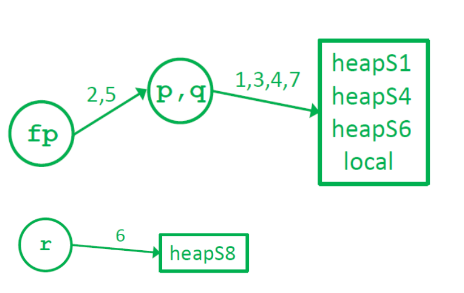 |
$P_{s5}$ = {$heapS_1, heapS_4, heapS_6, local$}
Pointer Analysis Using BDDs: Binary Decision Diagrams
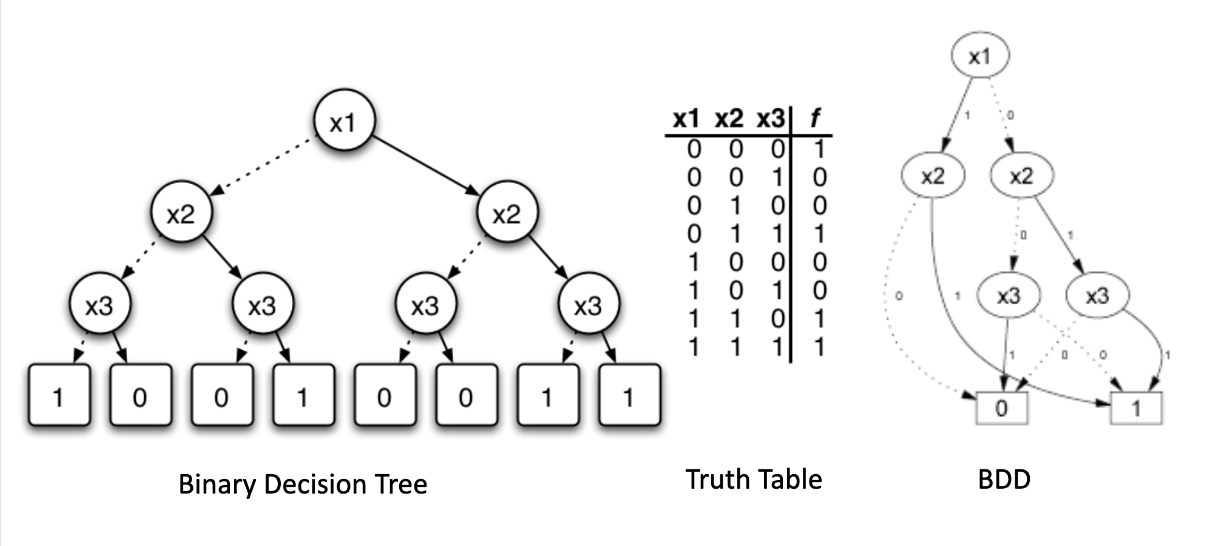
- Use a BDD to represent transfer functions
- Encode procedure as a function of its calling context
- Compact and efficient representation
- Perform context-sensitive, inter-procedural analysis
- Similar to dataflow analysis
- But across the procedure call graph
- Gives accurate results
- Scales up to large programs
Pointer Analysis: Yes, No, & Maybe
- Do pointers a and b point to the same location?
- Repeat for every pair of pointers at every program point
- How can we optimize the maybe cases?
Pointer Analysis: Data Speculative Optimization
- Implement a potentially unsafe optimization
- Verify and Recover if necessary
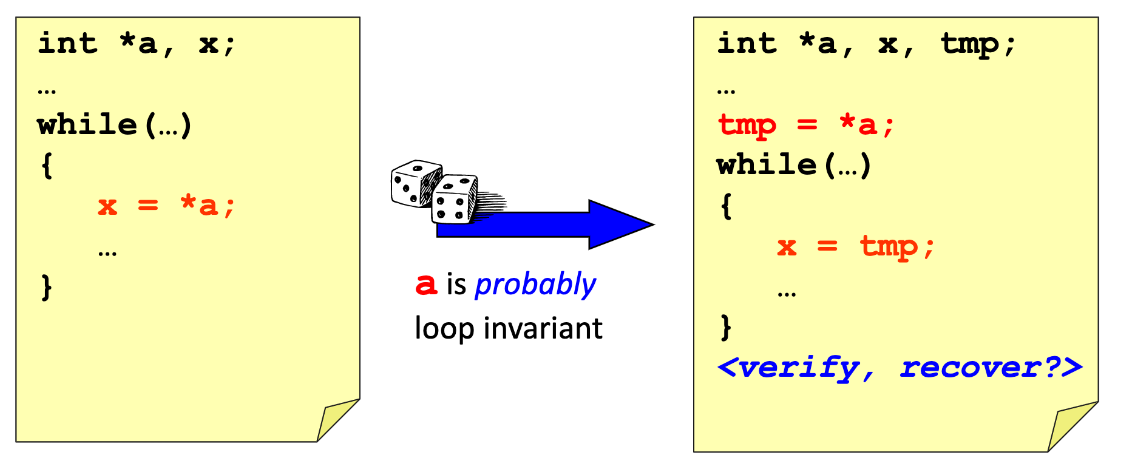
- EPIC Instruction sets
- Support for speculative load/store instructions
- Speculative compiler optimizations
- Dead store elimination
- Redundancy elimination
- Copy propagation
- Strength reduction
- Register promotion
- Thread-level speculation(TLS)
- Hardware and compiler support for speculative parallel threads
- Transactional programming
- Hardware and software support for speculative parallel transactions
Probabilistic Pointer Analysis
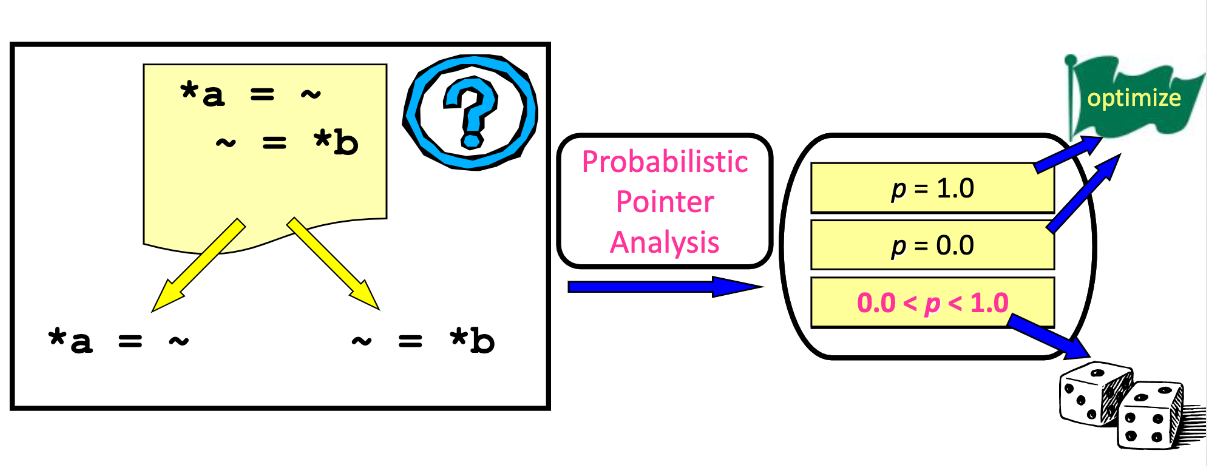
- Potential advantage of Probabilistic Pointer Analysis:
- It does not to be safe
- PRA Research Objectives:
- Accurate points-to probability information
- At every static pointer deference
- Scalable analysis
- Goal: Entire SPEC integer benchmark suite
- Understand scalability/accuracy tradeoff
- Through flexible static memory mode
- Accurate points-to probability information
- Algorithm Design Choices
- Fixed:
- Bottom Up / Top Down Approach
- Linear transfer functions (for scalability)
- One-level context and flow sensitive
- Flexible:
- Edge profiling (or static prediction)
- Safe (or unsafe)
- Field sensitive (or field insensitive)
- Fixed:
| Traditional Points-To Graph | Probabilistic Points-To Graph |
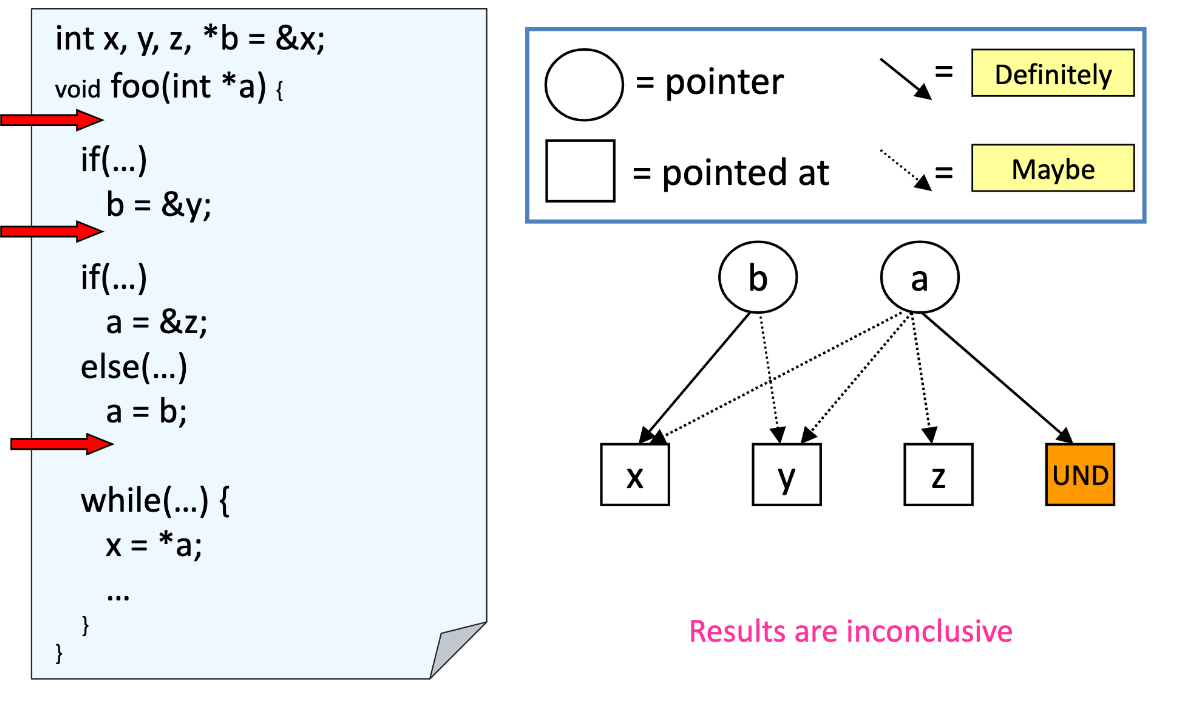 |
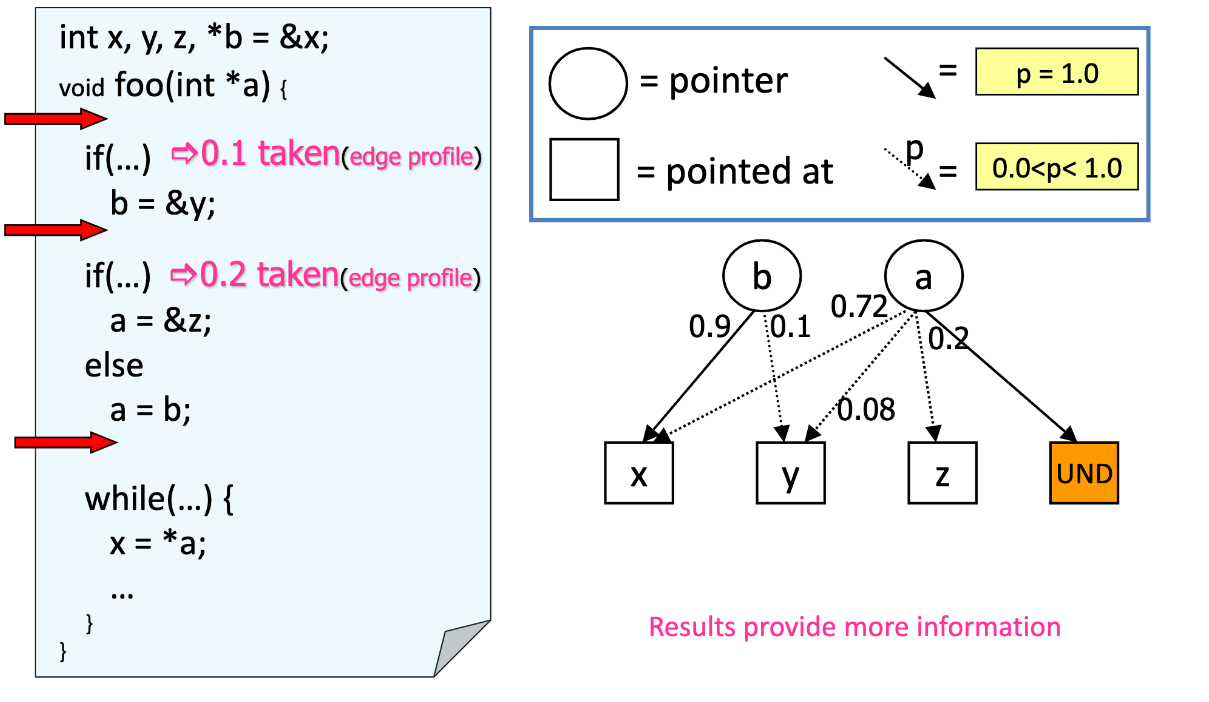 |
- PPA Result Summary:
- Matrix-based, transfer function approach
- SUIF/Matlab implementation
- Scales to the SPECint 95/2000 benchmarks
- One-level context and flow sensitive
- As accurate as the most precise algorithms
- Interesting result:
- Approximately 90% of pointers tend to point to only one thing
- Matrix-based, transfer function approach