Ideal Memory
- Zero access time (latency)
- Infinite capacity
- Zero cost
- Infinite bandwidth (to support multiple accesses in parallel)
The Problem
- Ideal memory’s requirements oppose each other
- Bigger is slower
- Bigger $\rightarrow$ Takes longer to determine the location
- Faster is more expensive
- Memory technology: SRAM, DRAM, Flash, Disk, Tape
- Higher bandwidth is more expensive
- Need more banks, more ports, higher frequency, or faster technology
Memory Technology: DRAM
- Dynamic random access memory
- Capacitor charge state indicates stored value
- Whether the capacitor is charged ir discharged indicates storage of 1 or 0
- 1 capacitor
- 1 access transistor
- Capacitor leaks through the RC path
- DRAM cell loses charge over time
- DRAM cell needs to be refreshed
Memory Technology: SRAM
- Static random access memory
- Two cross coupled inverters store a single bit
- Feedback path enables the stored value to persist in the “cell”
- 4 transistors for storage
- 2 transistors for access
Why Memory Hierarchy?
- We want both fast and large
- But we cannot achieve both with a single level of memory
- Idea: Have multiple levels of storage
- Progressively bigger and slower as the levels are father from the processor
- Ensure most of the data the processor needs is kept is the fast level
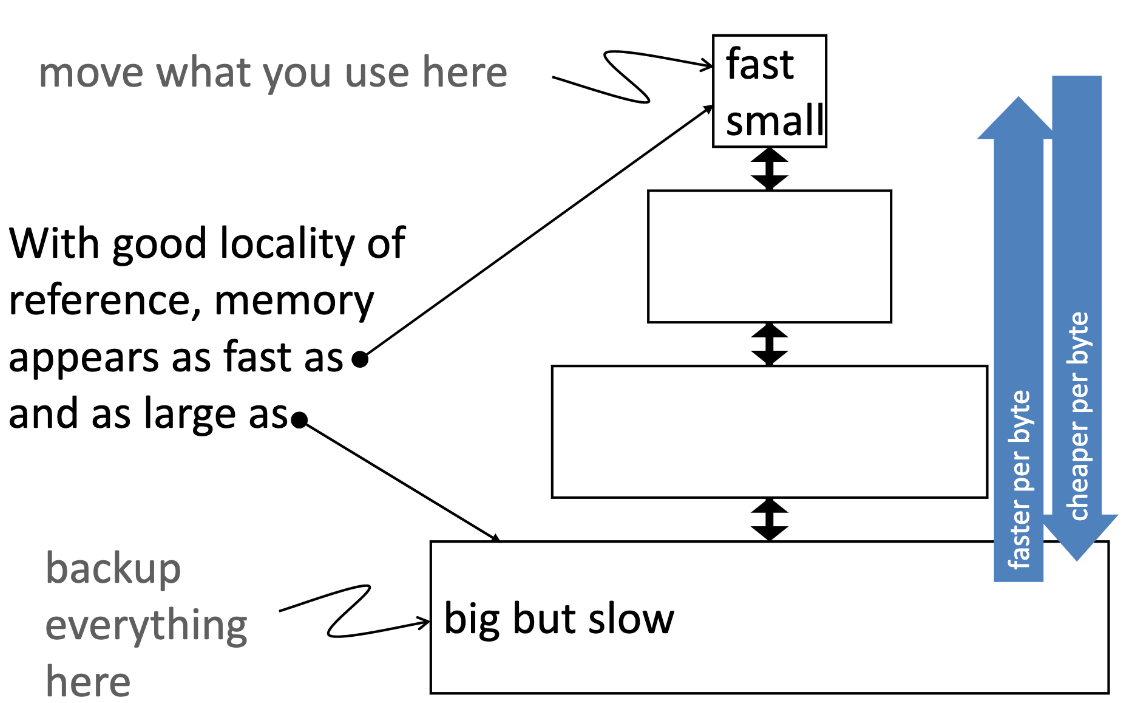
- Fundamental tradeoff:
- Fast Memory: Small
- Large Memory: slow
Caching Basics: Exploit Temporal Locality
- Idea: Store recently accessed data in automatically managed fast memory (called cache)
- Anticipation: The data will be accessed again soon
- Temporal locality Principle:
- Recently accessed data will be again accessed in the near future
Caching Basics: Exploit Spatial Locality
- Idea: Store addresses adjacent to the recently accessed one in automatically managed fast memory
- Logically divide memory into equal size blocks
- Fetch to cache the accessed block in its entirety
-
Anticipation: Nearby data will be accessed soon
- Spatial locality principle:
- Nearby data in memory will be accessed in the near future
- E.g., sequential instruction access, array traversal
- Nearby data in memory will be accessed in the near future
Optimizing Cache Performance
- Things to enhance:
- Temporal Locality
- Spatial Locality
- Things to minimize:
- conflicts(i.e. bad replacement decisions)
- Things We Can Manipulate:
- Time
- When is an object accessed?
- Space
- Where does an object exist in the address space?
- Time
Time: Reordering Computation
- What makes it difficult to know when an object is accessed?
- How can we predict a better time to access it?
- What information is needed?
- How do we know that this would be safe?
Space: Changing Data Layout
- What do we know about an object’s location?
- Scalars, structures, pointer-based data structures, arrays, code, etc.
- How can we tell what a better layout would be?
- How many can we create?
- To what extent can we safely alter the layout?
Iteration Space

- Each position represents an iteration
Optimizing the Cache Behavior Of Array Accesses
- We need to answer the following questions:
- when do cache misses occur?
- use Locality Analysis
- Can we change the order of the iterations (or possibly data layout) to produce better behavior
- Evaluate the cost of various alternatives
- Does the new ordering/layout still produce correct results?
- Use dependence analysis
- when do cache misses occur?
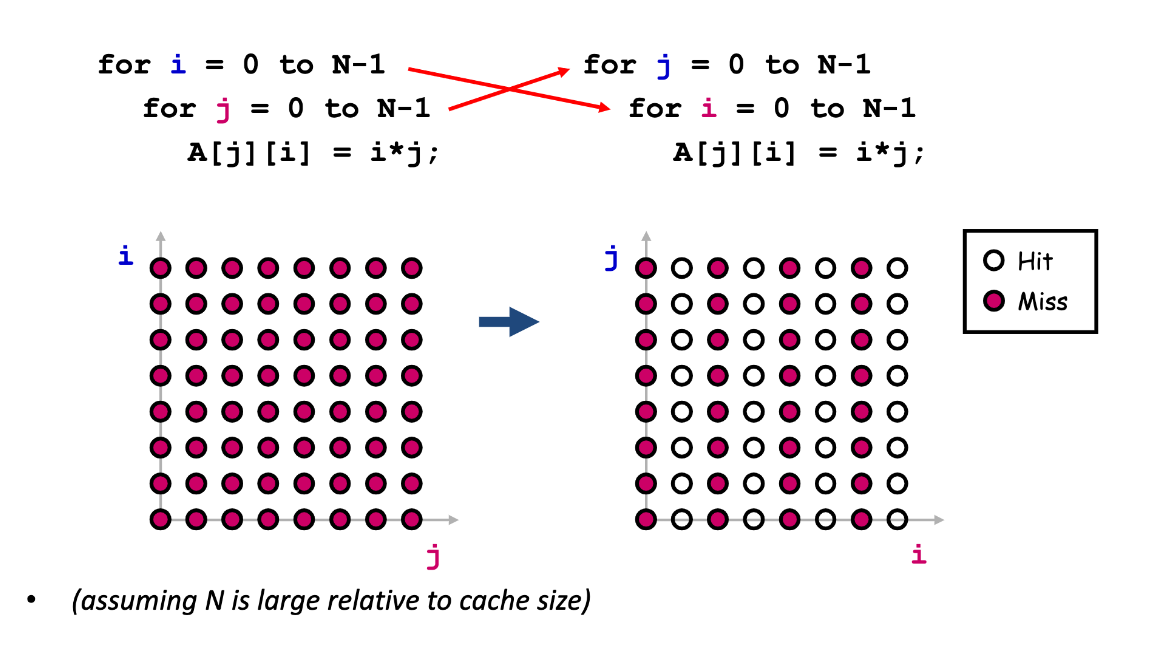
Loop Transformation: Loop Interchange
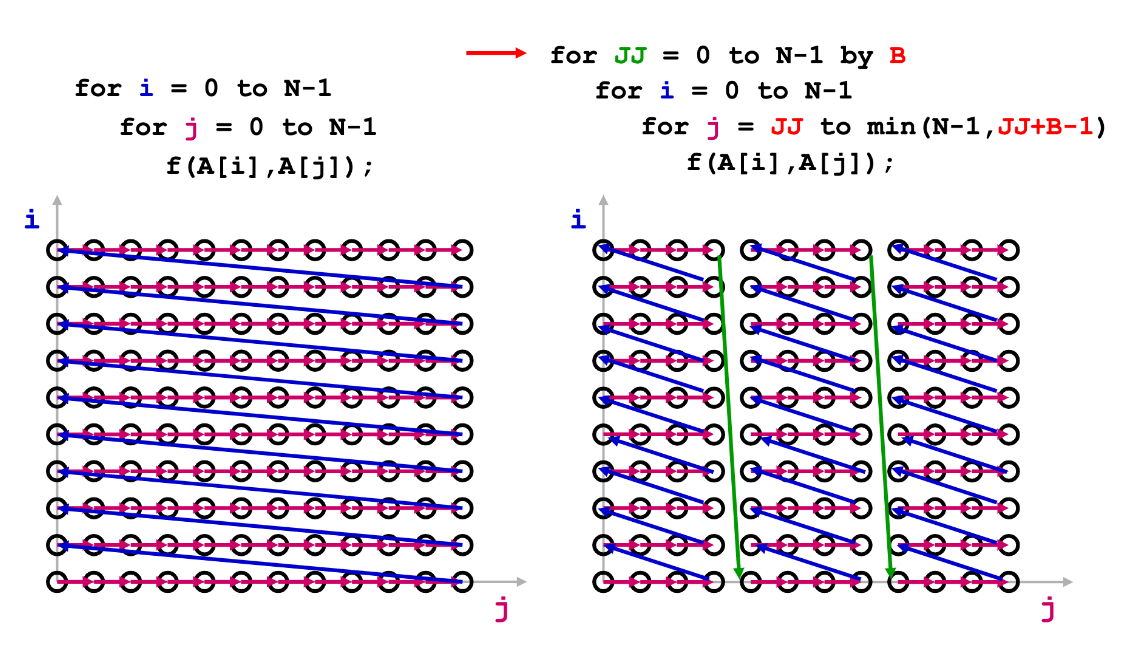
Loop Transformation: Cache Blocking
Locality Analysis
- Definition:
- Reuse:
- Accessing a location that has been accessed in the past
- Locality:
- Accessing a location that is now found in the cache
- Reuse:
- Key insights:
- Locality only occurs when there is reuse
- Steps:
- Find data reuse
- If caches were infinitely large, we would be finished
- Determine “localized iteration space”
- Set of inner loops where the data accessed by an iteration is expected to fit within the cache
- Find data locality:
- reuse $\cap$ localized iteration space $\rightarrow$ locality
- Find data reuse
- Types of Data Reuse/Locality
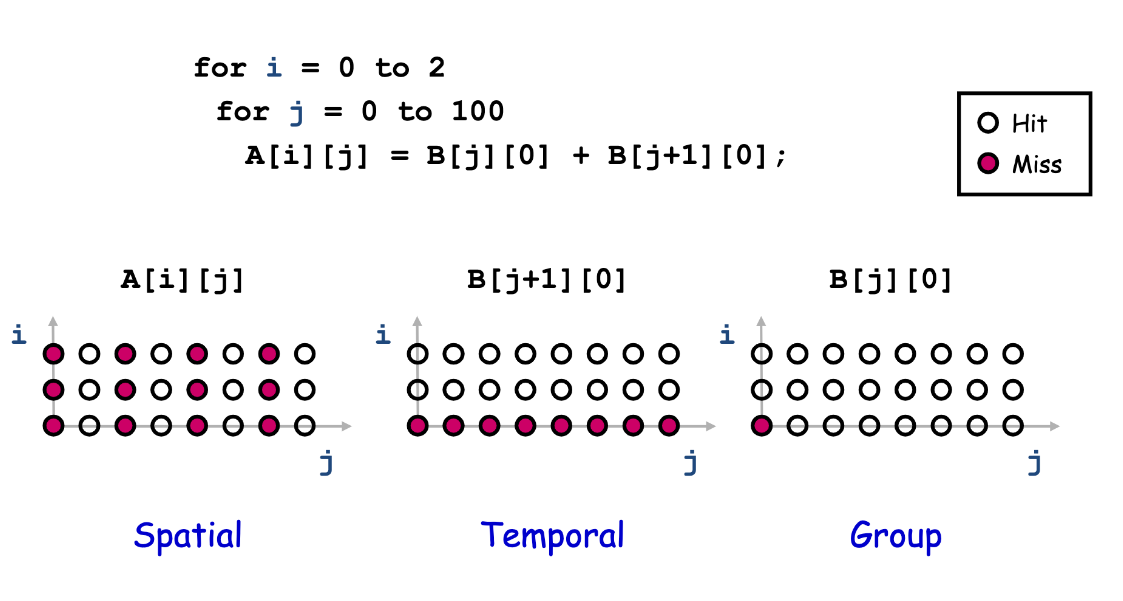
Reuse Analysis: Representation
1
2
3
for i = 0 .. 2
for j = 0 to 100
A[i][j] = B[j][0] + B[j+1][0];
Map n loop indices into d array indices via array indexing function
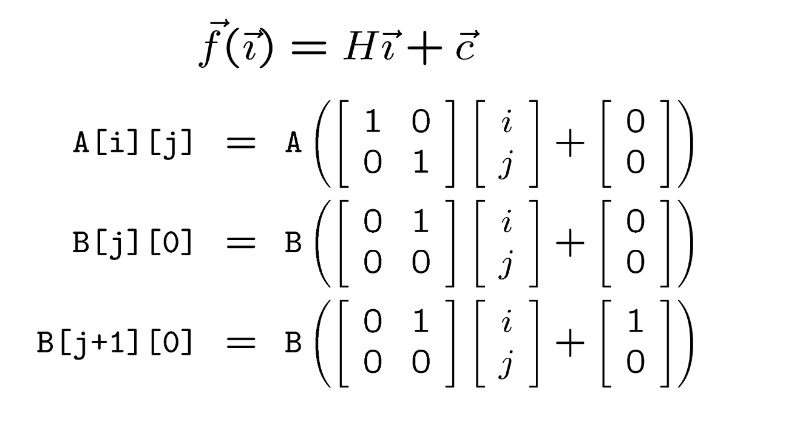
Finding Temporal Reuse
- Temporal reuse occurs between iterations $\bf\vec{i_1}$ and $\bf\vec{i_2}$ when:
- $\bf H\vec{i_1} + \vec{c} = H\vec{i_2} + \vec{c}$
- $\bf H(\vec{i_1} - \vec{i_2}) = \vec{0}$
- Rather than worrying about individual values $\bf\vec{i_1}$ and $\bf\vec{i_2}$, we say that reuse occurs along
direction $\bf \vec{r}$ vector when
- $\bf H\vec(r) = \vec{0}$
-
Solution: Compute the nullspace of H
-
Example:

- Example:

Computing Spatial Reuse
- Replace last row of H with zeros, creating $\bf H_s$
-
Find the nullspace of $\bf H_s$
-
Result: vector along which we access the same row
- Example:

-Example:

Computing Group Reuse
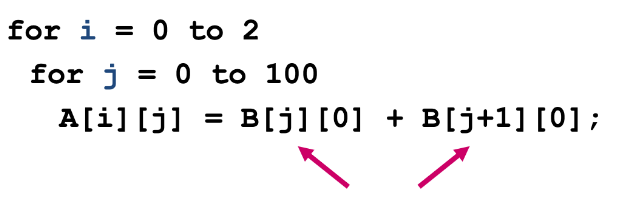
- Only consider “uniformly generated sets”
- Index expressions differ only by constant terms
- Check whether they actually do access same cache line
- Only the “leading reference” suffers the bulk of the cache misses
Localized Iteration Space
- Given finite cache, when does reuse result in locality?
- Localized if accesses less data than effective cache size

Computing Locality
- Reuse Vector Space $\cap$ Localized Vector Space $\rightarrow$ Locality Space

- If both loops are localized:
- span{(1, 0)} $\cap$ span{(1, 0), (0, 1)} $\rightarrow$ span{(1, 0)}
- i.e temporal reuse does result in temporal locality
- If only the innermost loop is localized
- span{(1,0)} $\cap$ span{(0, 1)} $\rightarrow$ span{}
- i.e no temporal locality