Coping with Memory Latency
- Reduce Latency:
- Locality Optimizations
- Reorder iterations to improve cache reuse
- Locality Optimizations
- Tolerate Latency:
- Prefetching
- Move data close to the processor before it is needed
- Prefetching
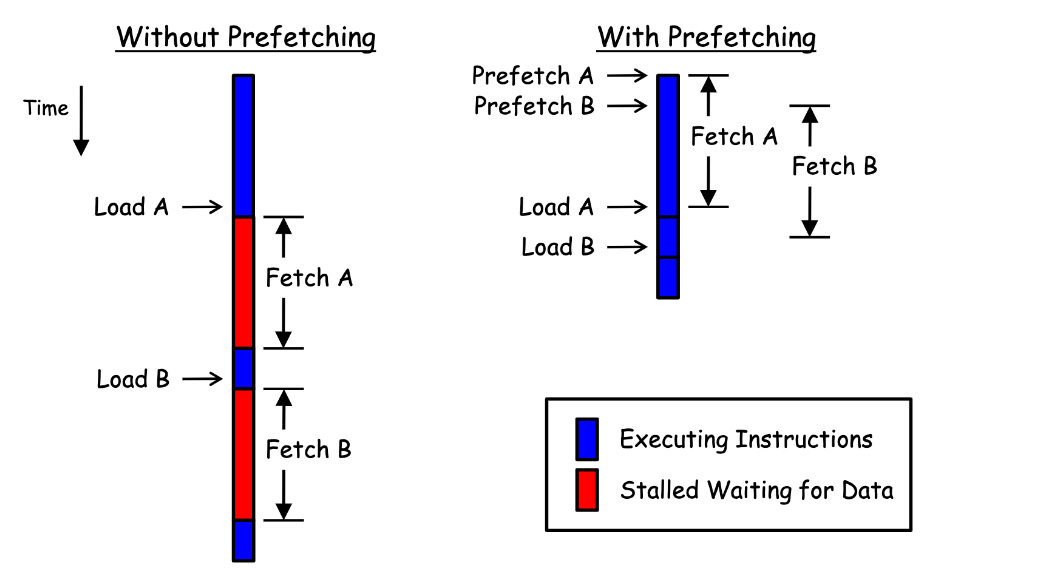
- overlap memory accesses with computation and other accesses
Prefetching
- Types of prefetching:
- Cache Blocks:
- Limited to unit-stride access
- Nonblocking Loads:
- Limited ability to move back before use
- Hardware-Controlled Prefetching:
- Limited to constant-strides and by branch prediction
- No instruction overhead
- Software-Controlled Prefetching:
- Software sophistication and overhead
- Minimal hardware support and broader coverage
- Cache Blocks:
- Prefetching Goals:
- Domain of Applicability
- Performance Improvement
- Maximize Benefit
- Minimize Overhead
Prefetching Concepts
- possible: Only if addresses can be determined ahead of time
- coverage factor: Fraction of misses that are prefetched
- unnecessary: If data is already in the cache
-
effective: If data is in the cache when later referenced
- Analysis: What to prefetch
- Maximize coverage factor
- Minimize unnecessary prefetches
- Scheduling: When/How to schedule prefetches
- Maximize effectiveness
- Minimize overhead per prefetch
- Compiler Algorithm
- Analysis:
- Locality Analysis
- Scheduling:
- Loop Splitting
- Software Pipelining
- Analysis:
Prefetch Predicate
| Locality Type | Miss Instance | Predicate |
| None | Every Iteration | True |
| Temporal | First Iteration | i = 0 |
| Spatial | Every l iteration (l = cache line size) |
(i mod l) = 0 |
1
2
3
for i = 0 to 2
for j = 0 to 100
A[i][j] = B[j][0] + B[j + 1]
| Reference | Locality | Predicate |
A[i][j] |
j: Spatial | (j mod 2) = 0 |
B[j+1][0] |
i: Temporal | i = 0 |
Loop Splitting
- Decompose loops to isolate cache miss instances
- cheaper than inserting IF statements
Locality Predicate Loop Transformation None True None Temporal i = 0 Peel loop i Spatial (i mod l) = 0 Unroll loop i by l - Apply transformations recursively for nested loops
- Suppress transformations when loops become too large
- avoid code explosion
Software Pipelining
Iteration Ahead = $\lceil \frac{l}{s} \rceil$
where l = memory latency, s = shortest path through loop body
-
Example:

-
Example:
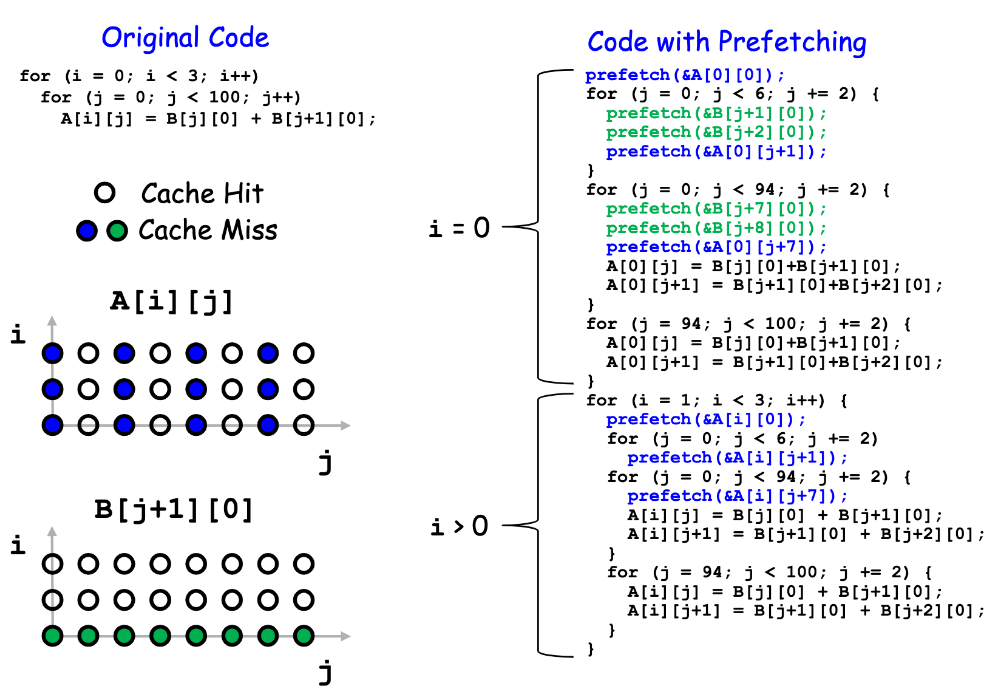
Prefetching Indirections
1
2
for (int i = 0; i < 100; i++)
sum += A[index[i]];
- Analysis: what to prefetch
- both dense and indirect references
- Difficult to predict whether indirections hit or miss
- Scheduling: when/how to issue prefetches
- modification of software pipelining algorithm

Prefetching for Recursive Data Structure
Recursive Data Structures
- Example:
- linked lists, trees, graphs
- A common method of building large data structures
- Especially in non-numeric programs
- Cache miss behavior is a concern because:
- Large data set with respect to the cache size
- Temporal locality may be poor
- Little spatial locality among consecutively-accessed nodes
- Goal:
- Automatic compiler-Based Prefetching for Recursive Data Structures
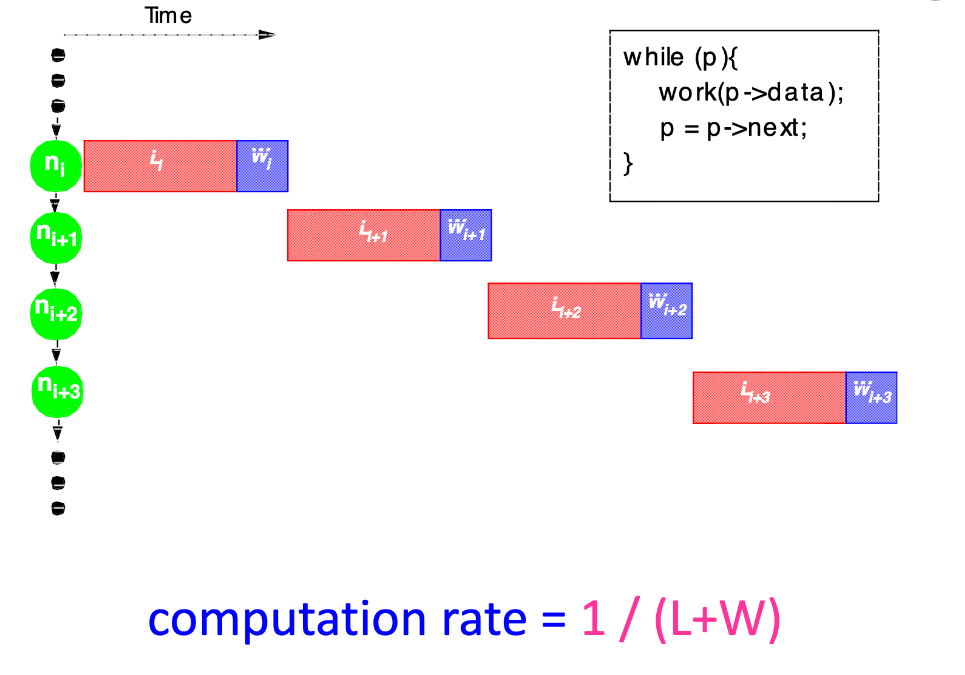
Scheduling Prefetches for Recursive Data Structures
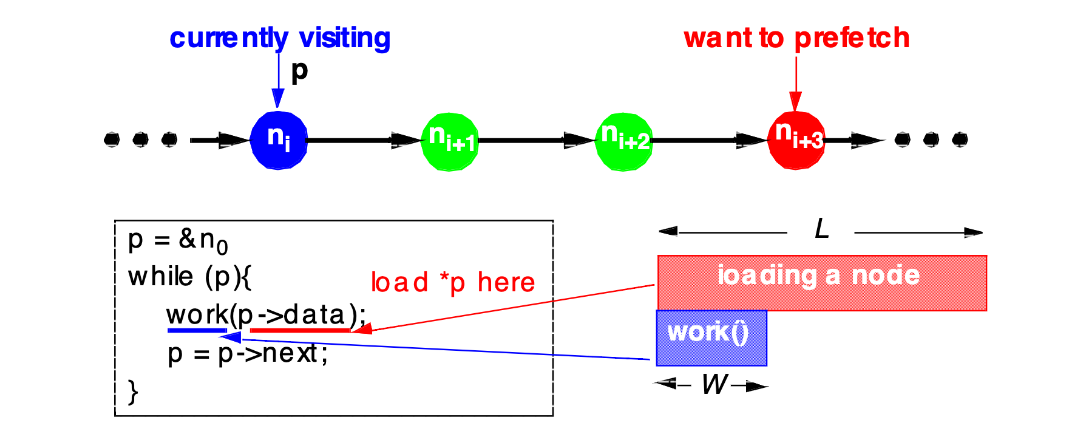
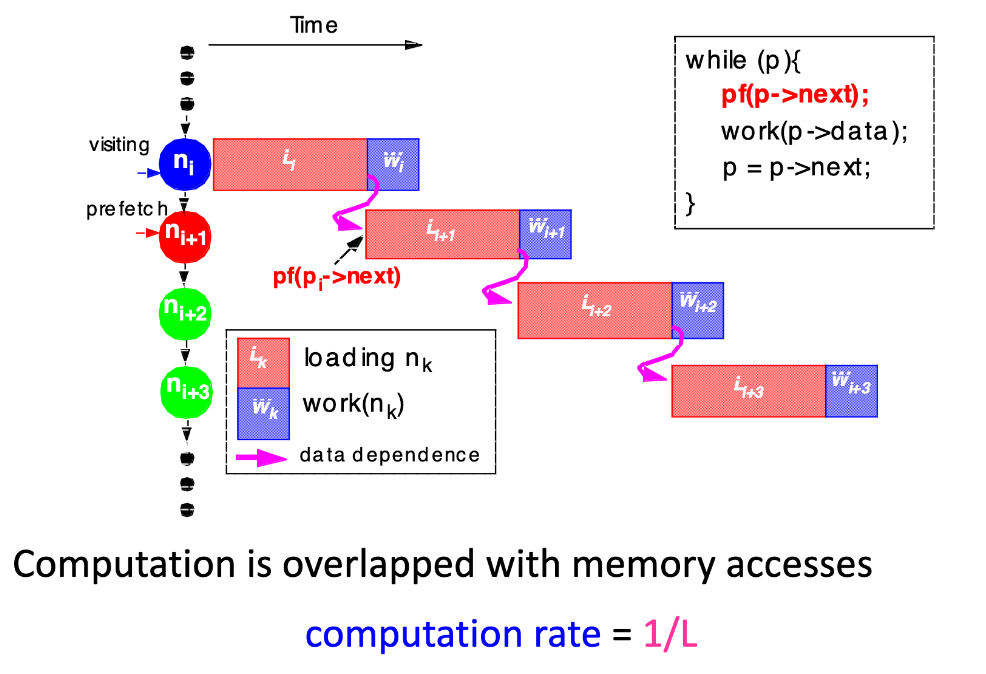
- Our Goal: fully hide latency
- Thus achieving fatest possible computation rate of $\frac{1}{W}$
- e.g., if L = 3W, we must prefetch 3 nodes ahead to achieve this
| No Prefetching | Prefetch One Node | Prefetch Three Nodes |
 |
 |
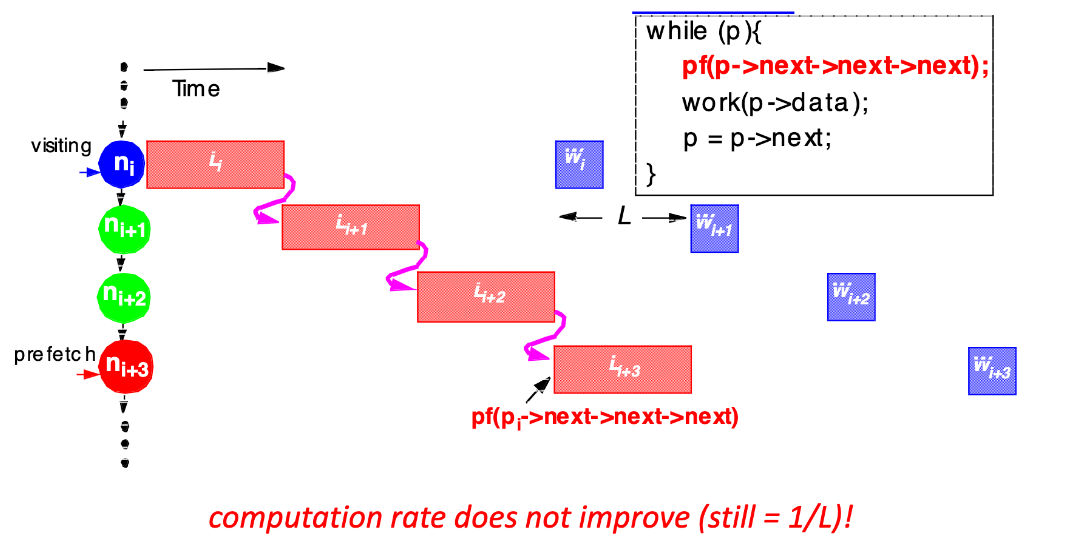 |
- Pointer-Chasing Problem:
- Any scheme which follows the pointer chain is limited to a rate of $\frac{1}{L}$
Pointer-Chasing Problem
- Key:
- $n_i$ needs to know &$n_{i + d}$ without referencing the d-1 intermediate nodes
- Our proposals:
- Use existing pointer(s) in $n_i$ to approximate &$n_{i+d}$
- Greedy Prefetching
- Add new pointer(s) to $n_i$ to approximate &$n_{i+d}$
- History-Pointer Prefetching
- Compute &$n_{i+d}$ directly from &$n_i$ (no pointer dereference)
- Data-Linearization Prefetching
- Use existing pointer(s) in $n_i$ to approximate &$n_{i+d}$
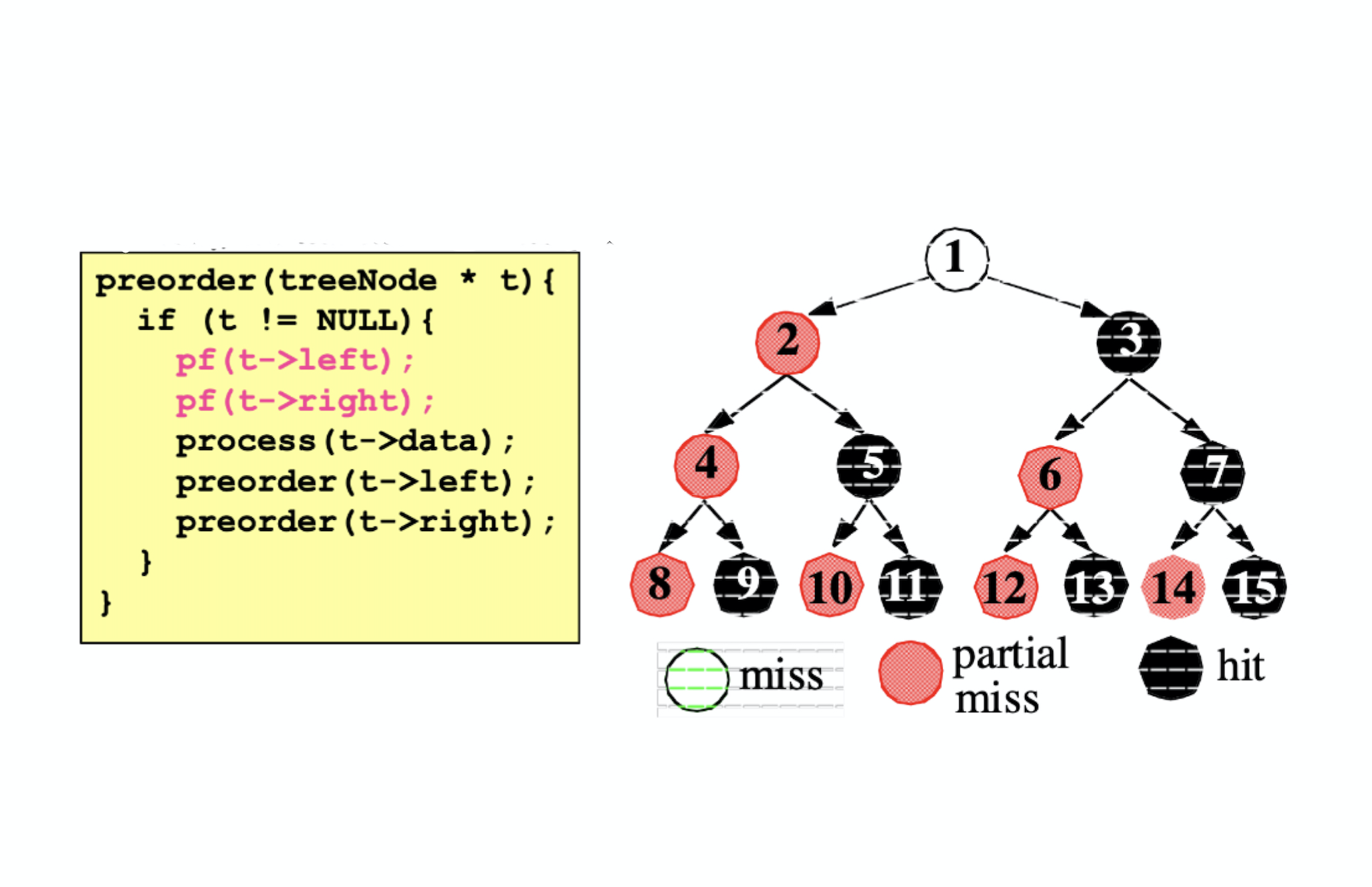
Greedy Prefetching
- Prefetch all neighboring nodes
- Only one will be followed by the immediate control flow
- Hopefully, we will visit other neighbors later
History-Pointer Prefetching
- Add new pointer(s) to each node
- History-pointers are obtained from some recent traversal
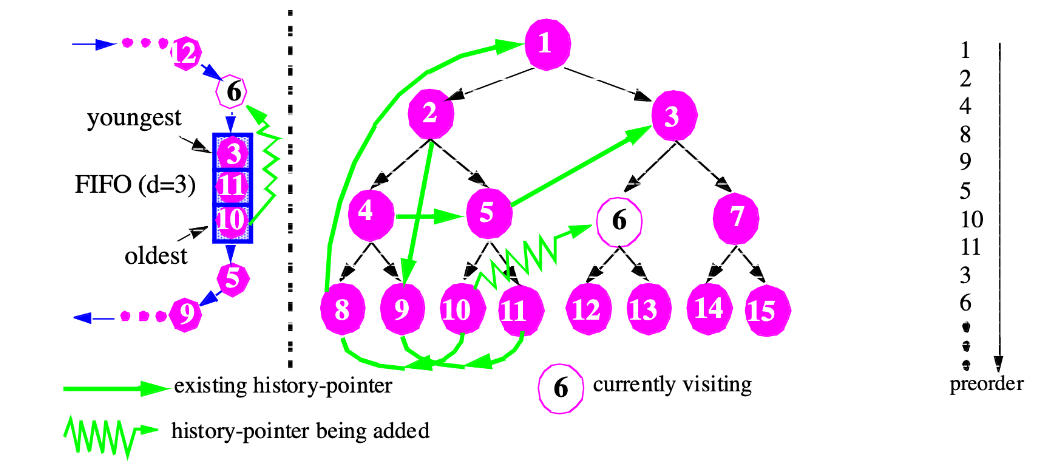
- Trade space & time for better control over prefetching distances
Data-Linearization Prefetching
- No pointer dereferences are required
- Map nodes close in the traversal to contiguous memory
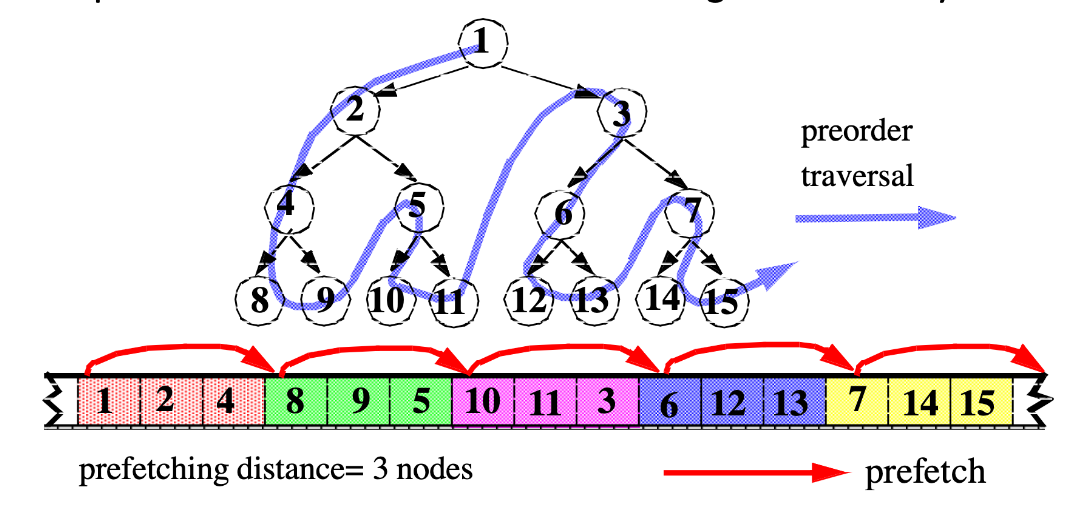
Summary Of Prefetching Algorithms
| Greedy | History-Pointer | Data-Linearization | |
| Control over prefetching Distance | Litter | More Precise | More Precise |
| Applicability to Recursive Dat Structures | Any RDS | Revisited Changes only slowly |
Must have a major traversal order Changes only slowly |
| Overhead in Preparing Prefetch Addresses | None | Space + Time | None in Practice |
| Ease of Implementation | Relatively Straightforward | More Difficult | More Difficult |