Scheduling
Sharing resources always results in contention
- A scheduling discipline resolves contention
- It determines which one goes next
- Key to fair sharing resources and providing performance guarantees
- Important for Quality of Service provisioning
Example of a web server
- Consider a set of queries made to a web server
- Each query represents a service request contending for shared resources
- The web server
- Assume the server can serve only one request at a time
- Requests that arrive when a server is busy must wait
- Each query represents a service request contending for shared resources
- A busy server holds an incoming request in a service queue
- The request will eventually be selected for service
- The queuing delay of a request is defined as the time between its arrival and eventual service
- The server allocates different mean queuing delays to different requests by its choice of service order
- The scheduling discipline of a server makes the decision
Scheduling disciplines
A scheduling discipline is important for
- Fairly sharing network resources
- Provide performance-critical applications
- Telephony and interactive multi-party games
- With Quality of Service guarantees
- It has two orthogonal components
- It decides the order in which requests are serviced
- It manages the service queue of requests awaiting service
- If packets cannot be served, and the service queue overflows, which one should be drooped?
- Intuition: Allocate different loss rates to different users
Where should we use scheduling? Usually studied in the literature for the output of a switch in the network layer
- In the web server example
- Used in the application layer
- In general
- Any layer dealing with a multiplexed resource must deal with scheduling
- Example: Job scheduling in datacenter clusters
- But only in packet-switched networks
- Circuit-switched networks do not need scheduling
Types of Applications
We expect two types of applications
- Best-effort applications (adaptive, non-real time, bulk)
- e.g. email, some types of file transfer
- The performance requirements are elastic
- They can adapt to the resource available
- Guaranteed-Service applications (non-adaptive, real time)
- e.g. Packet voice, interactive video, stock quotes
- Voice: Human ergonomic constraints require the round-trip delay to be smaller than 150ms
- Requires the network to reserve resources on their behalf
The performance received by a connection from a source to a destination depends on the scheduling discipline at each switch along the path
- A switch queues requests, represented by packets ready for transmission. in a per-link output queue
- At each output queue, a scheduling discipline is used to choose which ready packet to transmit next
What can a scheduling discipline do?
- Allocate different mean delays to different connections
- By a choice of service order
- Allocate different bandwidths to different connections
- By serving at least a certain number of packets from a connection
- Allocate different loss rates
- By giving more or fewer buffers
- Determine how fair the network is
- Even for best effort applications
Conservation Law
First-Come-First-Served(FCFS) is simple, but cannot differentiate among connections
But though a more complex scheduling discipline can achieve such differentiation, the sum of the mean queuing delays received by the set of connections weighted by their share of the link’s load is independent of the scheduling discipline
- If the scheduler is work-conserving
- It is idle only if its queue is empty
- Called the Conservation Law
- It implies that a scheduling discipline can only reallocate the delays
Requirements
An ideal scheduling discipline should
- Be easy to implement (Both guaranteed-service and best-effort applications)
- Be fair(For best-effort applications)
- Provide performance bounds(For guaranteed-service applications)
- Allow easy admission control decisions (For guaranteed-service applications)
- Decide whether a new flow can be allowed
Ease of Implementation
Scheduling discipline has to make a decision once every few microseconds
- Should be implementable in a few instructions or hardware
- For hardware: Critical constraint is the memory required to maintain scheduling state
- Pointers to packets queues
- For hardware: Critical constraint is the memory required to maintain scheduling state
- Work per packet should scale less than linearly with the number of active connections
- $O(N) is not good enough$
Fairness
Scheduling discipline allocates a resource
- An allocation is fair if it satisfies max-min fairness
- Each connection gets no more than what it wants
- The excess, if any, is equally shared
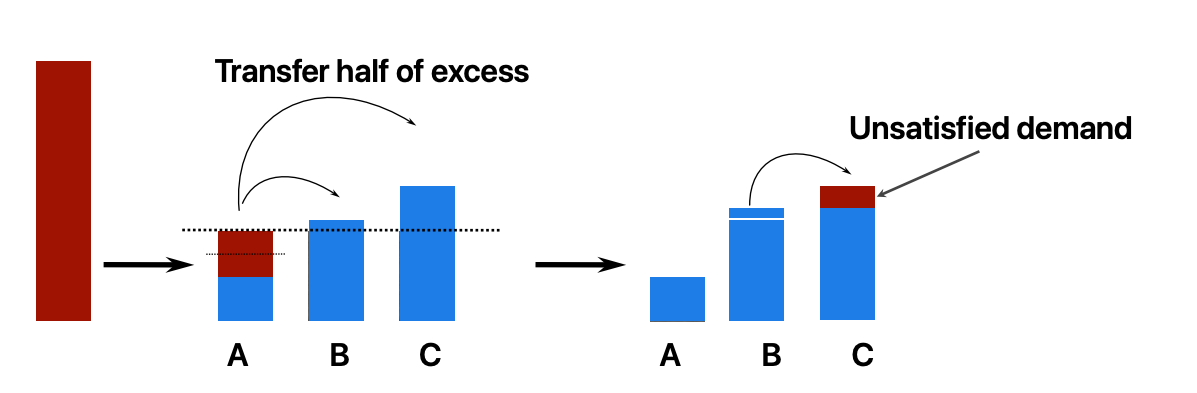
Fairness is intuitively a good idea
But it also automatically provides protection
- Traffic hogs cannot overrun others
- Automatically builds firewalls around heavy users
Fairness is a global objective, but a scheduling discipline takes only local resource allocation decisions
- To translate from a local decision to a global one
- Each connection should limit its resource usage to the smallest locally fair allocation along its path
Dynamics:
- Delay to regain global fairness
- Global fairness may never be achieved
Performance Bounds
A way to obtain an arbitrarily desired level of service
Restricted by the Conservation Law
- First-Come-First-Served(FCFS) will offer a tight lower bound in terms of the sum of delays
- A smaller delay in one connection
- Larger delays elsewhere
Can be expressed deterministically or statistically
- Every packet has a delay of no more than 100ms
- The probability that a packet has a delay > 10 ms is < 0.01
Contract between the user and operator An operator can guarantee performance bounds for a connection only be reserving some network resources
- During the call establishment phase of a connection
- But the amount of resources reserved depends on the connection’s traffic intensity
- Guaranteed-service connections must agree to limit their usage
- The relationship between the network operator and the user can be viewed as a legal contract
- The user agrees that its traffic will remain within certain bounds
- The operator guarantees that the network will meet the connection’s performance requirements
Bandwidth Specified as minimum bandwidth measure over a pre-specified interval
- E.g. at least 5Mbps over intervals of 1 sec
- Meaningless without an interval
- Can be bound on average (sustained) rate or peak rate
- Peak is measured over a small interval
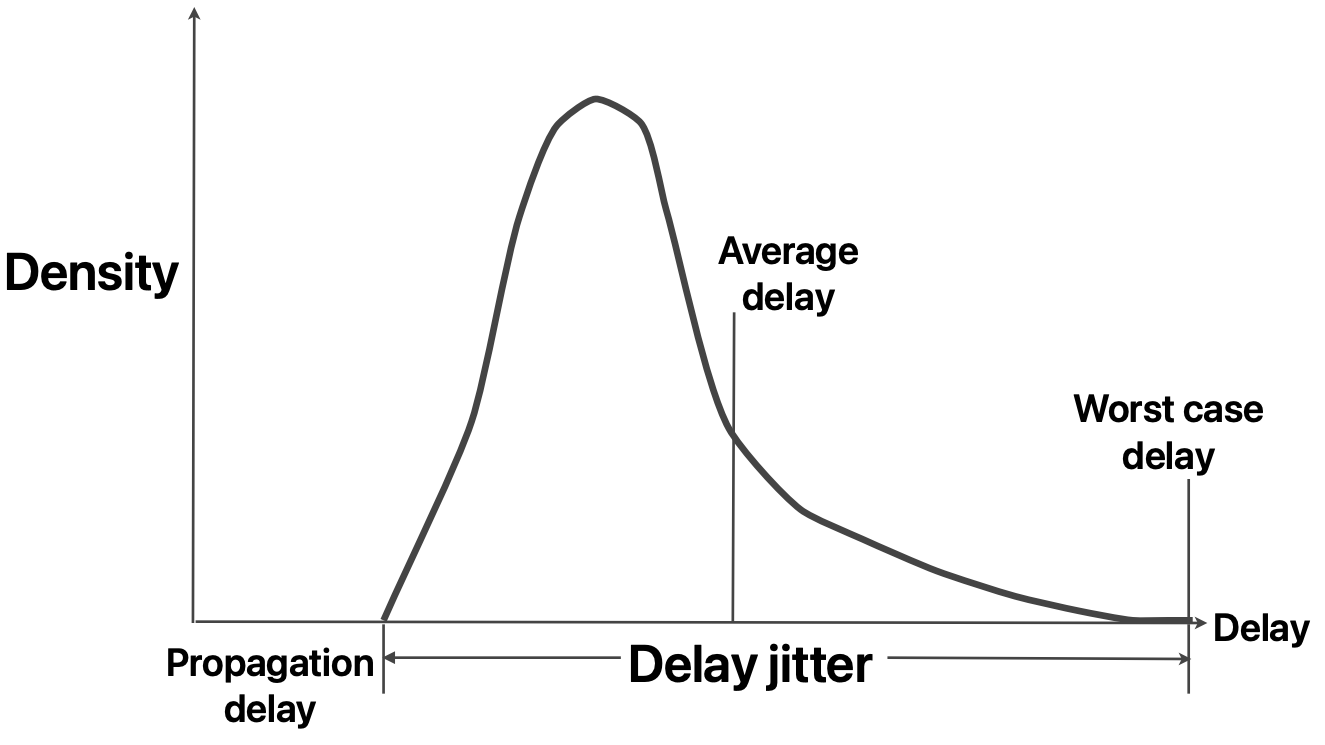
Delay and delay jitter Bound on some parameter of the delay distribution curve
Ease of Admission Control
Admission control is needed to provide Quality of Service
- Overloaded resource cannot guarantee performance
- The choice of scheduling discipline affects ease of admission control algorithm
Fundamental Choices
- Number of priority levels
- Work-conserving vs. non-work-conserving
- Degree of aggregation
- Service order within a priority level or aggregation class
Number of priority levels
Packet is served from a given priority level only if no packets exist at higher levels (multilevel priority with exhaustive service)
- Highest level gets lowest delay
- At least three are desirable
- High priority level: Urgent messages
- e.g. Network control
- Medium priority level
- Guaranteed service traffic
- Low priority level:
- Best-effort traffic
- High priority level: Urgent messages
- Watch out for starvation
Work-conserving
Work-conserving discipline is never idle when packets await service
Non-work-conserving
- Delay a packet till it is eligible
- Reduces delay jitter
- Smaller buffers in the network
- How to choose eligibility time?
- Rate-jitter regulator: Bounds maximum outgoing rate
- Delay0jitter regulator: Compensates for variable delay at previous hop
Do we need non-work-conserving disciplines?
- Can remove delay-jitter at an endpoint instead
- But also reduces size of switch buffers
- Increases mean delay
- Not a problem for playback application
- Wastes bandwidth
- Can serve best-effort packets instead
- Always punishes a misbehaving source
- Can;t have it both ways
- Bottom line: Not too bad, implementation cost may be the biggest problem
Degree of aggregation
More aggregation
- Less state
- Cheaper
- Smaller VLSI
- Less to advertise
- But: Less individualization
Solution
- Aggregate to a class, members of a class have same performance requirement
- No protection within class
Service order
In order of arrival (FCFS) or in order of a per-packet service tag Service tags: Can arbitrarily reorder queue
- Can achieve allocations that are close to max-min fair
- Both protection and delay bounds are also possible
- But need to sort queue, which can be expensive
FCFS
- Bandwidth hogs win (no protection)
- Rewards greedy behaviour (peer-to-peer networks)
- No guarantee on delays
Summary
Each feature comes at some cost of implementation
- For a small LAN switch
- Traffic loads are likely to be much smaller than the available capacity
- Service queues are small
- Users are cooperative
- A single FCFS scheduler, or a two-priority scheduler, should be sufficient
- For a heavily-loaded wide-area public switch
- Possibly non-cooperative users
- Protection is desirable
- Multiple priority levels, non-work-conserving at some priority levels
- Aggregation within some priority levels, and non-FCFS service order
Scheduling best effort connections
Main requirement is fairness Achievable using Generalized Processor Sharing(GPS)
- Visit each non-empty queue in turn
- Serve infinitesimal from each queue in a finite time interval
- Why is this max-min fair?
- How can we give weights to connections?
GPS is not implementable
- We cannot serve infinitesimals, only packets
No packet discipline can be as fair as GPS: but how closely?
- While a packet is being served, we are unfair to others
Define: work(i, a, b) = #bits transmitted for connection i in time [a, b]
Absolute fairness bound for scheduling discipline S
- $max(work_{GPS}(i, a, b) - work_{S}(i, a, b))$
Relative fairness bound for scheduling discipline S
- $max(work_{s}(i, a, b) - work_{s}(j, a, b))$
We can’t implement GPS. So let’s see how to emulate it We want to be as fair as possible But also have an efficient implementation
weighed Round Robin
Round Robin: Serve a packet from each non-empty queue in turn
Unfair if packets are of different length or wrights are not equal
Weighted Round Robin
- Different weights, fixed size packets
- Serve more than one packet per visit, after normalizing to obtain integer weights
- Different weights, variable size packets
- Normalize weights by mean packet size
- e.g. weights {0.5, 0.75, 1.0} mean packet size{50, 500, 1500}
- normalize weights: ${\frac{0.5}{50}, \frac{0.75}{500}, \frac{1.0}{1500}} = {0.01, 0.0015, 0.000666}$
Problems
- With variable size packets and different weights, need to know mean packet size in advance
- Fair only over time scales longer than a round time
- At shorter time scales, some connections may get more service than others
- If a connection has a small weight, or the number of connections is large, this may lead to long periods of unfairness
- For example
- T3 trunk with 500 connections, each connection has a mean packet size of 500 bytes, 250 with weight 1, 250 with weight 10
- Each packet takes $\frac{500 * 8}{45} = 88.8 microseconds$
- Round time $2750 * 88;8 = 244.2 ms$
Deficit Round Robin (DRR)
DRR modifies weighted round-robin to allow it to handle variable packet sizes without knowing the mean packet size of each connection in advance
- It associates each connection with a deficit counter, initialized to 0
- It visits each connection in turn, trie to serve one quantum worth of bits from each visited connection
- A packet at the head of queue is served if it is no larger than the sum of quantum, and the deficit counter (which is then adjuted)
- If it is larger, the quantum is added to the connection’s deficit counter
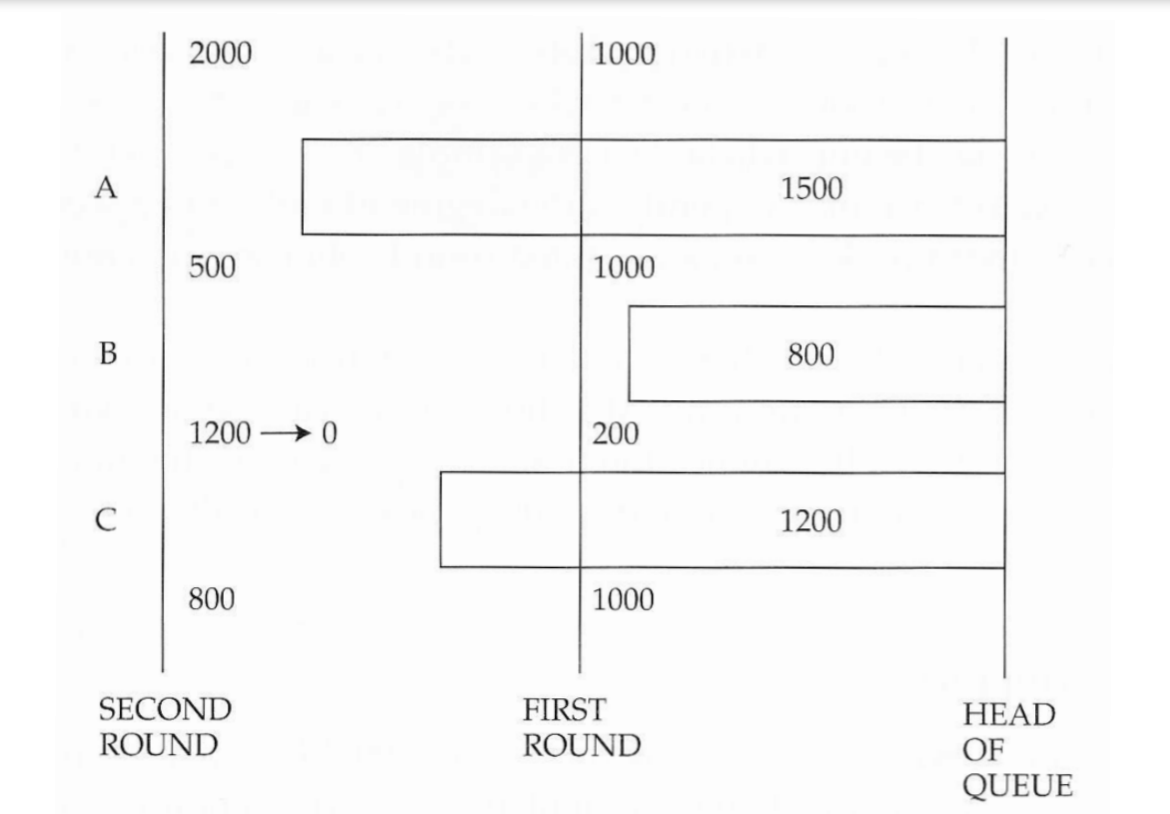
Pro:
- Ease of implementation
- Relative fairness bound: $3 * \frac{F}{r}$ where F is the frame time (the largest possible time taken to serve each of the backlogged connections), and r is the rate of the server
Con:
- Unfair at time scales smaller than a frame time
- For example
- T3 trunk (45 Mbps) with 500 connections and a packet size of 8 Kbytes, the frame time is
- As large as 728 ms
Suitable when fairness requirements are loose or when packets are small
Weighted Fair Queuing(WFQ)
Deals better with variable size packets and wights
- Do not need to know a connection’s mean packet size in advance
Basic Idea
- Simulates GPS “on the side” and uses the results to determine service order
- Compute the time a packet would complete service (finish time), had we been serving packets with GPS, bit by bit
- Then serve packets in order of their finish times
- The finish time is just a service tag, and has nothing to do with the actual time at which the packet is served
- We can more appropriately call it a finish number
First cut
- Suppose in each round, the server served on ebbit from each active connection
- Round number is the number of rounds already completed
- Can be fractional
- If a packet of length p bits arrives to an empty queue when the round number is R, it will complete service when the
round number is $R + p =>$ finish number is $R + p$
- Independent of the number of other connections
- If a packet arrives to a non-empty queue, and the previous packet has a finsih number of f, then the packet’s finish number is $f + p$
- Serve packets in the order of finish number
A catch
- A queue may need to be considered non-empty even if it has no packets in it
- e.g. packets of length 1 from connections A and B, on a link of speed 1bit/sec
- At time 1, packet from A served, round number = 0.5
- A has no packets in its queue, yet should be considered non-empty, because a packet arriving to it at time 1 should have finish number 1+p
- e.g. packets of length 1 from connections A and B, on a link of speed 1bit/sec
- Solution:
- A connection is active if the last packet served from it, or in its queue, has a finish number greater than the current round number
To sum up, assuming we know the current round number R
- Finish number of packet of length p
- If arriving to active connection = previous finish number + p
- If arriving to an inactive connection = R+p
- To implement WFQ, we need to know two things
- Is the connection active?
- If not, what is the current round number?
- Answer to both quetions depends on computing the current round number
Computing the round number
- Naively: Round number = number of rounds of service completed so far
- What if a server has not served all connections in a round?
- What if new connections join halfway through a round?
- Redefine round number as a real-valued variable that increases at a rate inversely proportional to
the number of currently active connections
- This takes care of both problems
- With this change, WFQ emulates GPS instead of bit-by-bit Round Robin
Example
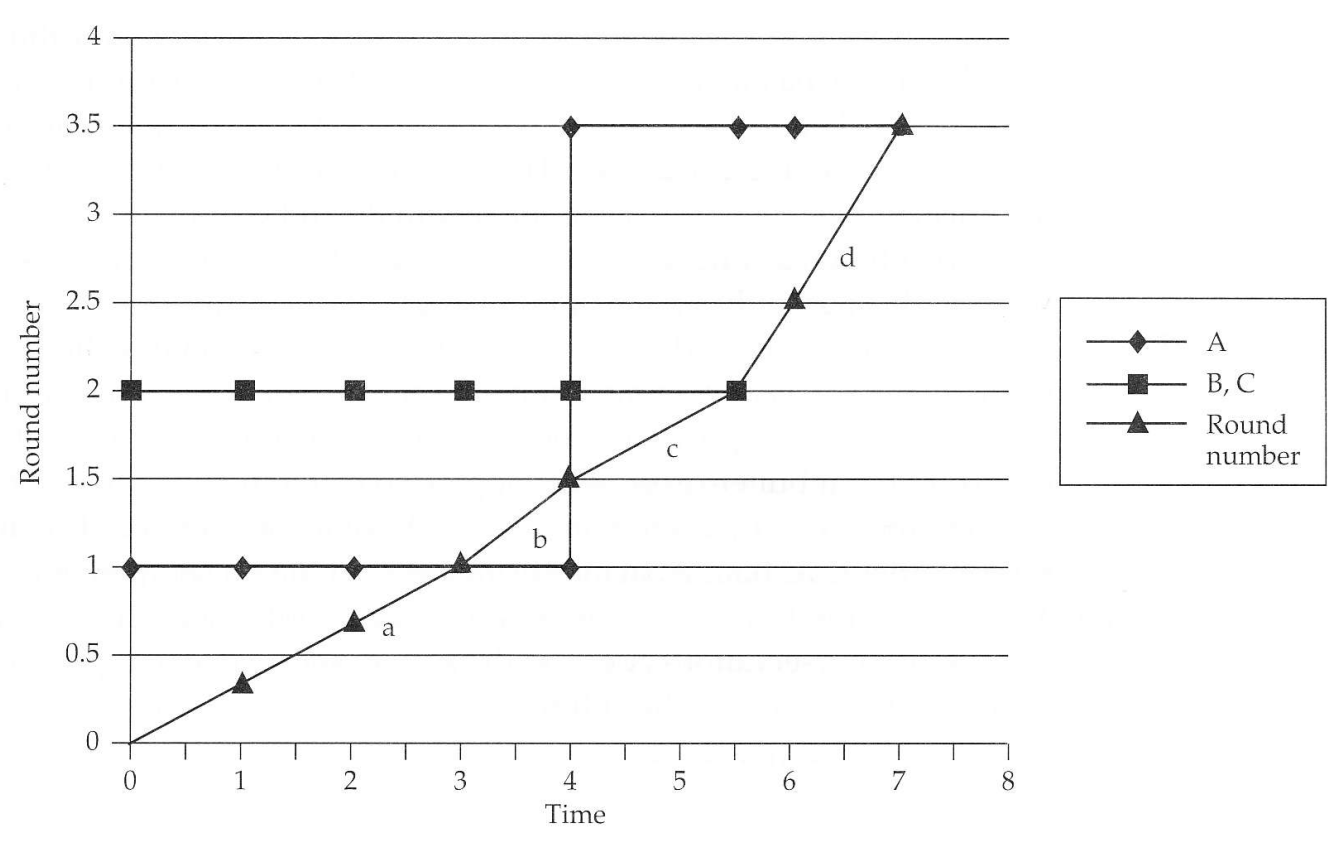
- Packets of size 1, 2, and 2 units arrive at a WFQ scheduler at time 0, on equally weighted connections A, B, and C
- A packet of size 2 arrives at connection A at time 4
- The link service rate is 1 unit/second
- Questions
- What are the finish number of all packets?
- What is the round number when the system becomes idle?
- When does this happen?
Problem: Iterated Deletion Suppose the round number at time 0 is 0 and has a slope of $\frac{1}{5}$
- We may incorrectly suppose that, at time 5, it would have a value of 0 + $\frac{1}{5} * 5 = 1$
- However, our computation may be wrong, because one of the five connections active at time 0 may become inactive before time 5
- Say connection 1 becomes inactive at time 4, so at time 5, the slop of the round number line increases from $\frac{1}{5}$ to $\frac{1}{4}$
- At time 5, the round number would be $4 * \frac{1}{5} + 1 * \frac{1}{4} = 1.05$
- Suppose connection 2 has a finish number smaller than 1.05
- It would also become inactive before time 5, further affecting the slope of the round number
- Which may delete mmore connections
- It would also become inactive before time 5, further affecting the slope of the round number
A server recomputes the round number on each packet arrival and departure
At any re-computation, the number of connections can go up at most by one, but can go down to zero
To solve this problem
- Use previous count to compute round number
- If this makes some connection inactive, recompute
- Repeat until no connections become inactive
On packet arrival
- Use the source and destination address to classify it to a connection, and look up the finish number of the last packet served
- Recompute round number
- Compute finish number
- Insert in a priority queue sorted by finish numbers
On service completion
- Select the packet with the lowest finish number in the priority queue
If GPS has served x bits from connection A by time t
WFQ would have served at least $x - P_{max}$ bits, where $P_{max}$ is the largest possible packet in the network
Pro:
- Like GPS, it providess protection
- Can obtain worst-case end-to-end delay bound
- Gives users incentive to use intelligent flow control
Cons:
- Needs per-connection state
- Iterated deletion is complicated
- Requires explicit sorting of the output queue
Virtual Clock
Tag values are not computed to emulate GPS
- Instead, a VC scheduler emulates time-division multiplexing in the same way that WFQ emulates GPS
- A packet’s finish number = $max(previous finsih number, real time) + p$
- Replaced round number with real time
- But relative fairness bound is infinity if not all connections are backlogged
Scheduling guaranteed-service connections
With best-effort connections, the goal is fairness
With guaranteed-service connections
- What performance guarantees are achievable?
- How easy is admission control?
Weighted Fair Queuing revisited
- Turns out that WFQ also provides performance guarantees
- Bandwidth bound
- Ratio of $weights * link capacity$
- Example:
- Connections with weights 1, 2, 7
- Link capacity 10 connections get at least 1, 2, 7 units of bandwidth each
- End-to-end delay bound
- Assumes that the connection doesn’t send too much
- More precisely, connection should be leaky-bucket regulated
Leak-bucket regulators Implement linear bounded arrival processes
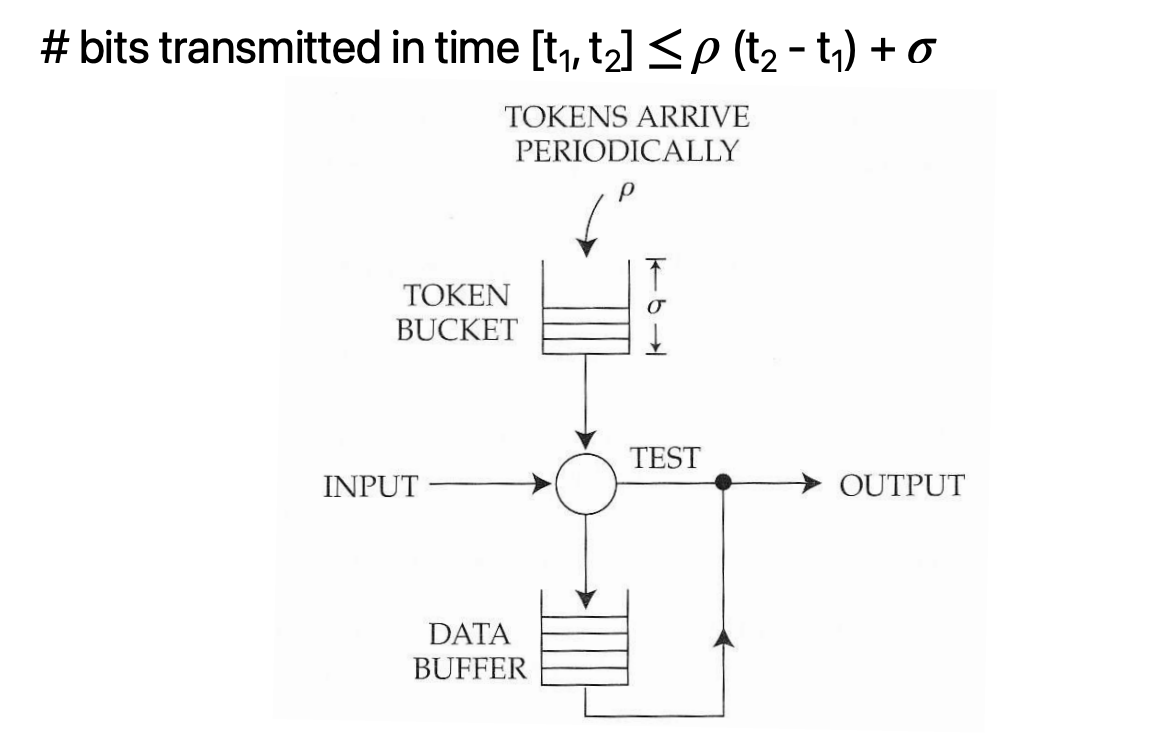
Special cases of a leaky-bucket regulator Peak-rate regulator: Setting the token-bucket limit to one token, and the token replenishment interval to the peak rate
Augment a leaky-bucket regulator with a peak-rate regulator:
- controls all three parameters:
- The average rate,
- The peak rate,
- The largest burst
Parekh-Gallager Theorem
Let a connection be allocated weights at each WFQ scheduler along its path, so that the least bandwidth it is allocated is g
Let it be leaky-bucket regulated such that #bits sent in time $[t_1, t_2] \le \rho (t_2 - t_1) + \sigma$
Let the connection pass through K schedulers, where the kth scheduler has a link rate r(k)
Let the largest packet allowed in the network be P
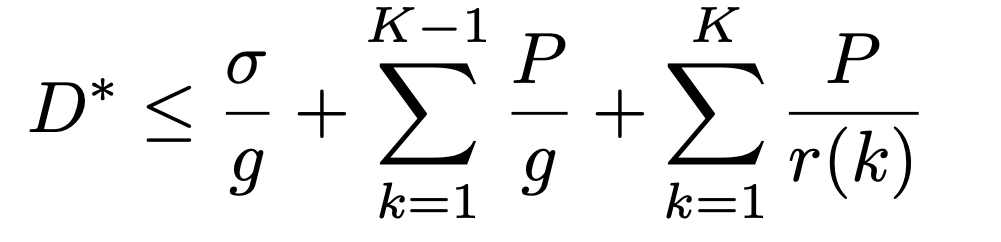

Theorem shows that WFQ can provide end-to-end delay bounds
So WFQ provides both fairness and performance guarantees
Bound holds regardless of cross traffic behaviour
Problems
- To get a delay bound, need to pick g
- The lower the delay bounds, the larger g needs to be
- Large g => exclusion of more competitors from link
- g can be very large, in our example > 80 times the peak rate
- WFQ couples delay and bandwidth allocations
- Low delay requires allocating more bandwidth
- Wastes bandwidth for low-bandwidth low-delay sources
Summary
- Two sorts of applications
- Best effort
- Guaranteed service
- Best effort connections require fair service
- Provided by GPS, which is unimplementable
- Emulated by WFQ and its variants
- Guaranteed service connections require performance guarantees
- Provided by WFQ, but this is expensive
- May be better to ise rate-controlled schedulers