Network
Every complex computer system involves one or more communication links, usually organized to form a network
The basic abstractions across the board
- send(message)
- receive(message)
The design of communication networks is dominated by three intertwined considerations:
- A trio of fundamental physical properties
- The mechanics of sharing
- A remarkably wide range of parameter values
A trio of fundamental physical properties
- The speed of light is finite
- It takes 20 milliseconds to transmit a signal across 2600 miles from Boston to Los Angeles
- Going to and from a geostationary satellite perched 22,400 miles above the equator: 244 milliseconds — large enough for a human to notice!
- Propagation delay
- There is no way to avoid it without moving the two cities closer together!
- Communication environments are hostile
- Radio signals, wires, and optical fibers must traverse far more hostile environments — under the floor, deep in the ocean
- Much easier to break: wiping out individual bits, severing cables
- Communication media have limited bandwidth
- Every transmission medium has a maximum rate at which one can transmit distinct signals
- This maximum rate is determined by its physical properties, such as the distance between transmitter and receiver and the attenuation characteristics of the medium
- Signals can be multilevel, not just binary, so the data rate can be greater than the signaling rate
- However, noise limits the ability of a receiver to distinguish one signal level from another
- The combination of limited signaling rate, finite signal power, and the existence of noise limits the rate at which data can be sent over a communication link
A network design must deal with
- Propagation delay: range over a few orders of magnitude
- Lack of reliability: Errors may occur
- Bandwidth: Also range over a few orders of magnitude
Communication links are always shared
Sharing arises for two distinct reasons
- Any-to-any connection: when you wish to communicate between any pair of computers, dedicated links connecting
all pairs are no longer feasible
- The number of computers a network should connect also spans a wide range of a few orders of magnitude
- Sharing of communication costs: Some parts of a communication system follow Moore’s law as they are silicon
- Other parts, such as building cables deep in the ocean or launching a satellite, are not getting cheaper
Wide range of parameter values
Propagation delays, date rates, the number of communicating computer: All spanning a range of several orders of magnitude
Another wide-ranging parameter
- Load: A single computer may at different times present a network with widely differing loads, ranging from transmitting a file at 30 megabytes per second to interactive typing at a rate of one byte per second!
Designing a network as a system is hard due to these considerations:
- Unyielding physical limits
- Sharing of facilities
- Existence of four different parameters that can each range over seven or more order of magnitude
- propagation delay
- data rates
- the number of communicating computers
- Load
The significant consequences of sharing
Consider a multiplexed communication link an in a telephone network between Boston and Los Angeles.
If there is an earthquake in Los Angeles and a “flash crowd” of incoming phone calls from Boston
The multiplexed link has a limited capacity
At some point the next caller will get a network is busy signal
Assume each call is 64 kilobits/sec, and the multiplexed link runs at 45 megabits/sec
A call runs at 8000 frames/sec, each frame is an 8-bit block
In between each pair of frames belonging to the call there is room for 702 other frames, carrying bits belonging to other phone calls
The entire link can carry up to 703 simultaneous calls
- $45 * 1000000 / 64 * 1000$
The 704th person will receive the network busy signal
Hard-edged: No resistance to the first 703 calls, but absolutely refuses the 704th call!
Time-division multiplexing
Time-division multiplexing(TDM), used in telephony, is very suitable for voice calls
- Provides a constant rate of data flow, and the delay from one end to the other is the same for every frame
But there is one prerequisite
- The must be some prior arrangement between the sending switch, and the receiving switch
A connection requires
- Some previous communication between the two switches to set it up storage for remembered state at both ends of the link some method to discard (tear down) that remembered state at the end
Data network
Why do data networks use a different strategy?
Data is being sent in bursts on an irregular basis - We can call these bursts messages
- Compared with the continuous stream of bits that flows out of a simple digital telephone
Bursty traffic: ill-suited to fixed size and spacing of isochronous frames
A system designed will be happy to give up the guarantee of uniform data rate and uniform latency - If in return an entire message can get through more quickly
This trade-off is achieved using asynchronous multiplexing - The sampling rate is different for each of the signals and a common clock is not required
Packet
The receiver is no longer able to figure out where the message in the frame is destined by simply counting bits
Each frame must include a few extra bits that provide guidance about where to deliver it
A variable-length frame together with its guidance information is called a packet
Guidance information can include the destination address of the message
Also need some way of figuring out where each frame starts and ends, a process known as framing
Asynchronous communication offers the possibility of connectionless transmission - No state need to be maintained on the switches about particular end-use communications (packets are usually called datagrams)
An additional complication: most links place a limit on the maximum size of a frame - When a message is larger than this maximum size, it is necessary for the sender to break it up into segments - Each of which the network carries in a separate packet - Include enough information with each segment to allow the original message to be reassembled at the other end
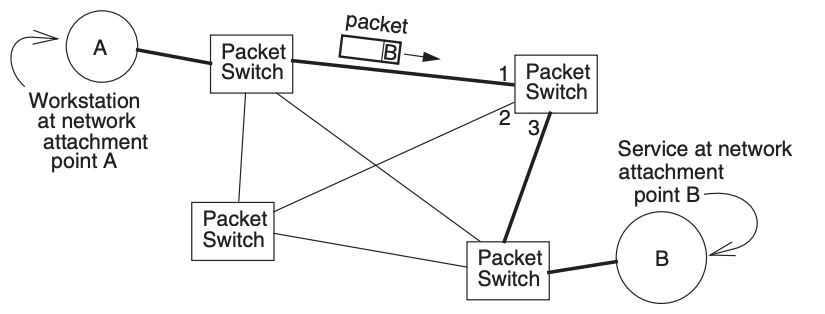
A packet going from A to B may follow several different paths or routes - choosing a particular path for a packet: routing - Choosing an outgoing link on a packet switch forwarding(using table look up)
Propagation delay
The time required for the signal to travel across a link is determined by the speed of light in the transmission medium connecting the packet switches, and the physical distance the signals travel
Transmission delay
Since the frame that carries the packet may be long or short, the time required to send the frame at one switch - and receive it at the next switch - depends on the data rate of the link and the length of the frame
Processing delay
Time for a switch to decide which outgoing link to forward a packet to, and to place the packet in the outgoing link’s buffer
Queuing delay
When the packet from A to B arrives at the upper right packet witch, link#3 may already be transmitting another packet, perhaps one that arrived from link #2, and there may also be other packets queued up waiting to use link #3
If so, the packet witch will hold the arriving packet in a queue in memory until it has finished transmitting the earlier packets
The duration of this delay depends on the amount of other traffic passing through that packet switch, so it can be quite variable
Queuing delay as a function of utilization
Asynchronous systems introduced a fundamental trade-off: if we limit the average queuing delay, it will be necessary to leave unused, on average, some capacity of each link!
- If we allow the utilization to approach 100%, delays will grow without bound
- The asynchronous design have replaced the abrupt appearance of the busy signal of the isochronous network with a gradualtrade trade-off: as the system becomes busier, the delays increase
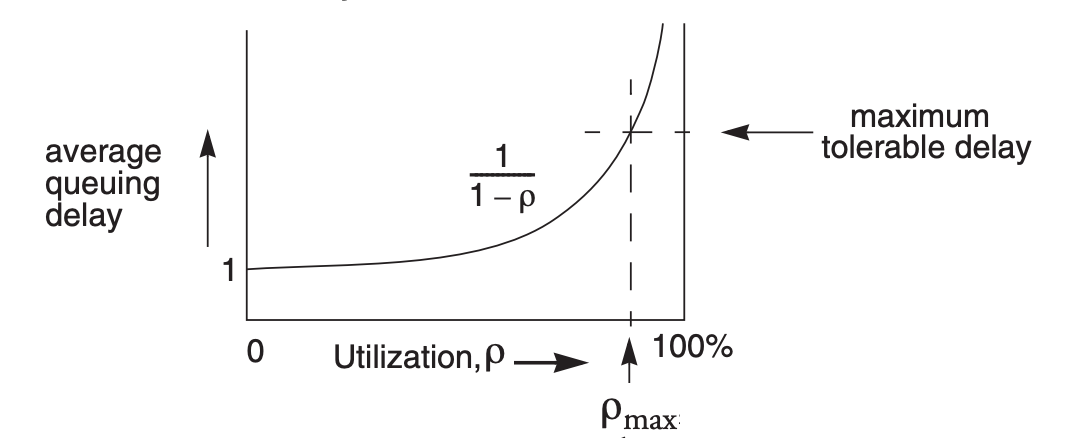
Maximum queuing delays
The figure is just about average queuing delays under ideal conditions - If we are serious about keeping the maximum delay almost always below a given value, we must prepare for occasional worse peaks by holding utilization well below the level of $\rho_{max}$ suggested by the previous figure
Queuing theory is not useful in predicting the behaviour of a network
In practice, network systems put a bound on link queuing delays by limiting the size of queues and by exerting control on arrivals - Effectively shifting delays to other places in the network
Design buffer size
Three strategies to design the buffer size:
-
Plan for the worse case: Examine the network traffic carefully, figure out what the worst-case traffic situation will be, and allocate enough buffers to handle it
-
Plan for the usual case and fight back: Based on a similar calculation, choose a buffer size that will work most of the time, and if the buffers fill up send messages back through the network asking someone to stop sending
-
Plan for the usual case and discard overflow:Choose a buffer size that will work most of the time, and ruthlessly discard packets when the buffers are full
Planing for the worst case
Buffer memory is usually inexpensive, so planning for the worst case seems like an attractive idea?
- But it is actually much harder than it sounds!
- Impossible to figure out what the worse case is in a large network
- Packets will queue up for too long in the large buffer: the sender may abort
- Go for the average (usual) case, then?
- What do we do when traffic will exceed the average for long enough to run out of buffer space — a congestion?
Fight back
If buffer space begins to run low, send a message back along an incoming link saying “please don’t send any more until you hear from me” - Such a “quench” request may go to the upstream packet switch, or all the way back to the original source
Harder than it sounds, too - If a packet switch is experiencing congestion, there is a good chance that the adjacent switch is also congested - if it is not already congested, it soon will be if it is told to stop sending data over the link to this switch - Sending an extra message is adding to the congestion - Worse, a set of packet switches configured in a cycle can easily end up in a form of deadlock: all buffers filled and waiting for the OK signal
Back to source
Problematic, too
- It may not be clear to which source to send the quench
- Such a request may not have any effect because the source you choose to quench is no longer sending anyway, by the time the quench request reaches there
- Assuming that the quench message is itself forwarded back
through the packet-switched network, it may run into congestion
and be subject to queuing delays
- The busier the network, the longer it will take to exert control!
- Even if all the data is coming from one source, by the time the quench gets back and the source acts on it, the packets already in the pipeline may exceed the buffer capacity
Discarding packets
When the buffers fill up, the switches start throwing packets away
- Sound like an awful choice!
- Eventually each discarded packet will have to be sent again so the effort to send the packet this far will have been waster
- But unfortunately, this is the only choice left
- It leads to a remarkable consequence
- Automatic rate adaptation: the sender of a packet can interpret the lack of its acknowledgment as a sign that the network is congested, and can in turn reduce the rate at which it sends new packets into the network
Forwarding networks
The possibility that a network may actually discard packets to cope with congestion leads to a useful distinction between two kinds of forwarding networks
- Best-effort network: If a network switch cannot dispatch a packet
soon after receipt, it may discard it (therefore providing a best-effort
contract to its users)
- Usually in a lower network layer
- The Internet
- Guaranteed-delivery network: It takes heroic measures to avoid every discarding payload data
- Usually in a higher network layer
- The Internet e-mail delivery
Duplicate
Problem 1: Duplicate Requests
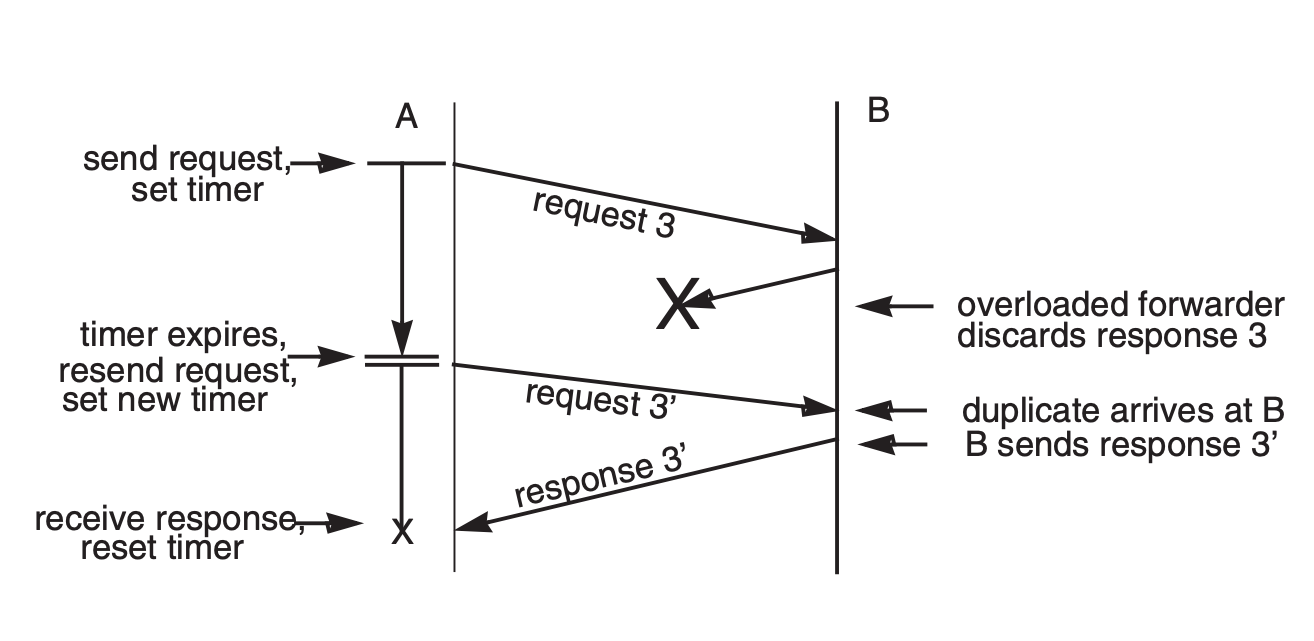
Problem 2: Duplicate Responses
Duplicate Suppression
The general procedure to suppress duplicates has two component
- Nonces
- Each request includes a nonce, which is a unique identifier that will never be reused by A when sending requests to B
- Example in previous figures: Use monotonically increasing serial numbers as nonces
- Receiver must keep a list of nonces
- If a duplicate is received, do not take action, but resend the previous response
Broken message
Damaged packets: Detected by error detection algorithms (such as using a checksum)
- Once detected, simply discarded by intermediate packet switches
Broken links: Needs more flexibility in routing
Reordered delivery: May be caused by following different paths - Needs additional information to reconstruct packet oder at the receive - It is not wise for the network system to maintain order
Isochronous vs. asynchronous multiplexing
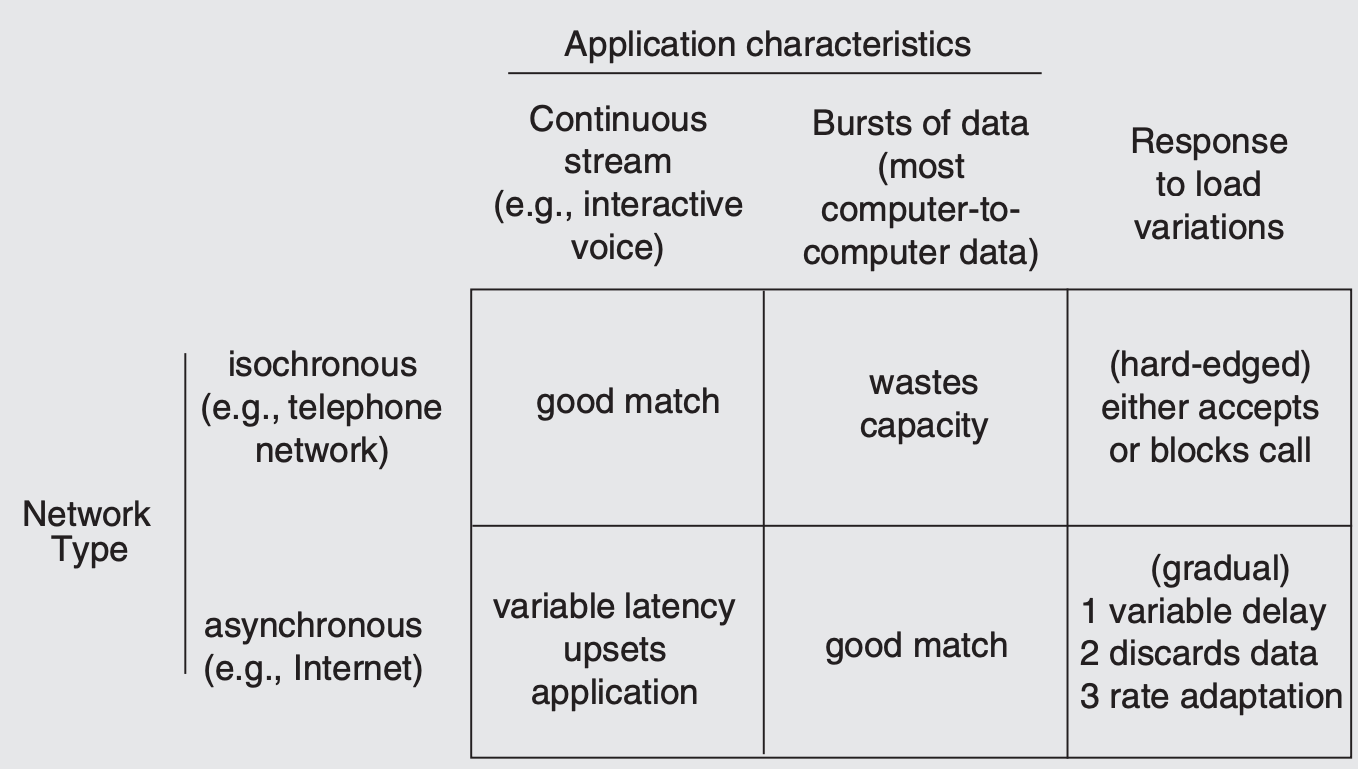
Adopt Sweeping Simplifications
Fundamental design principle: Adopt sweeping simplifications so you can see what you are doing
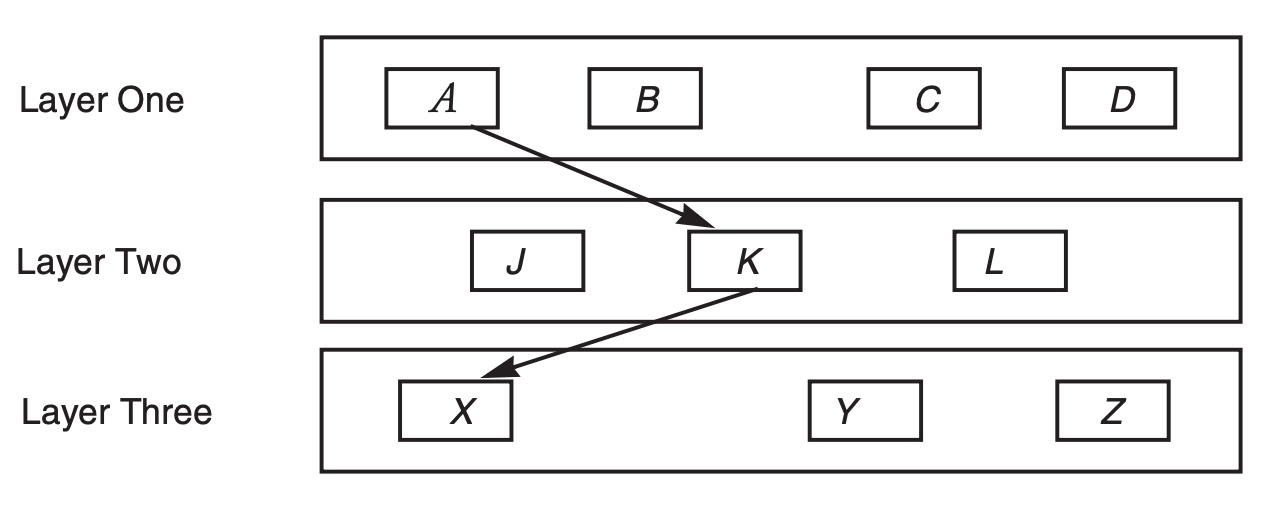
All networks use the divide-and-conquer technique known as layering of protocols
Module A may call any of the modules J, K, or L, but A doesn’t even know the existence of X, Y, and Z
The figure here shows A using module K. Module K, in turn, may call any of X, Y, or Z
Analogy: Post office
Consider a customer who walks into a post office to send a letter to a friend
Postal delivery involves an exchange of a message between two sets of parties - called “peer entities” - The customers, who view the postal network as a black that accepts letters at one end and delivers them to another - The postal workers, who handle the letters on behalf of their customers
Advantages of Protocol Layering
The set of rules that peer entities need to follow when they communicate with each other is called a protocol
Three advantages of protocol layering
- It allows a complex problem to be broken into smaller, more manageable pieces
- The implementation detail can be hidden (abstracted) from other layers - we can change it without disturbing the rest of the protocol stack
- Many upper layer protocols can share the services provided by the same lower layer protocol
Problems of Protocol Layering
Should we design upper layer protocols with the knowledge of implementation detail of a lower layer protocol? - Of course not, it violates the layering principle and defeats information hiding
But sometimes information hiding leads to poor performance - An upper layer protocol can throttle the source sending rate when detecting a packet loss, with the knowledge that a lower layer protocol will drop packets when congestion occurs
The art is to leak enough information between layers to allow efficient performance, but not so much that it is hard to change the implementation of a layer!
How many layers do we need?
At the minimum, three
- The link layer: Moving data directly from one point to another
- The network layer: Forwarding data through intermediate points to move it to the place it is wanted
- The end-to-end layer: Everything else required to provide a comfortable application interface
Perhaps we can also divide the link layer into the physical layer and the data link layer
Or divide the end-to-end layer into the transport layer and the application layer
It will then become a total of 5 layers
One end-to-end layer or four layers
Different applications have radically different requirements for transport, session, and presentation services!
- Even to the extent that the order in which they should be applied may be different
- This situation makes it difficult to propose any single layering, since a layering implies an ordering
- Any implementation decisions that a lower layer makes may be counterproductive for at least some applications
Instead, it is likely to be more effective to provide a library of service modules that can be selected and organized by the developer of a specific application
Sending and receiving data using layers
An application starts by asking the end-to-end layer to transmit a message or a stream of data to a correspondent
The end-to-end layer:
- Splits long messages and streams into segments
- Copes with lost or duplicated segments
- Places arriving segments in proper order
- Enforces specific communication semantics
- Performs presentation transformations
- Finally, calls on the network layer to transmit each segment
Typical services in the end-to-end layer Presentation services: Translating data formats and emulating the semantics of a procedure call
- Remote Procedure Call (RPC) Transport services: Dividing streams and messages into segments and dealing with lost, duplicated, and out-of-order segments
- Using serial numbers of the segments Session services: Negotiating a search, handshake, and binding sequence to locate and prepare to use a service that knows how to perform the requested procedure
- Session Initiation Protocol (SIP)
The network layer:
- Accepts segments from the end-to-end layer
- Constructs packets, and transmits those packets across the network
- Choosing which links to follow to move a given packet from its origin to its destination
The link layer:
- Accepts packets from the network layer
- Constructs and transmits frames across a single link between two forwarders or between a forwarder and a customer of the network
The end-to-end argument
The argument against additional layers constitutes part of a design principle
Fundamental design principle: The end-to-end argument
- The application knows best
The basic idea of the end-to-end argument is that the application knows best what its real communication requirements are, and for a lower network layer to try to implement any feature other than transporting the data risks implementing something that is not quite what the application needed.
Moreover, if it is not exactly what is needed, the application will probably have to re-implement that function on its own.
Don’t bury it in a lower layer, let the end points deal with it because they know best what they need!
A simple example:careful file transfer
To transfer a file carefully, the appropriate method is to calculate a checksum from the contents of the file as it is stored in the file system of the originating site
After the file has been transferred and written to the new file system, the receiving site should read the file back out of its file system, recalculate the checksum anew, and compare it with the original checksum
If the two checksums are the same, the file is correctly transferred
An end-to-end approach of checking the accuracy of the file transfer
- Is there any value in having the link layer add a frame checksum?
Despite this protection, the data may still be damaged!
- While it is being passed through the network layer
- While it is buffered by the receiving part of the file transfer application
- While it is being written to the disk
Therefore, the careful file transfer application cannot avoid calculating its end-to-end checksum, despite the protection provided by the link layer checksum!
Is the link layer checksum worthless?
- With a checksum, the link layer will discover data transmission errors at a time when they can be easily corrected by resending just one frame.
- Rather than redoing the entire file transfer
There may be a significant performance gain in having a feature in the lower-level layer
This implies that a lower-layer checksum does not eliminate the need for the application layer to implement the function
- It is thus not required for application correctness
It is just a performance enhancement
System Design
What is system design?
- A computer network provides computation, storage and transmission resources
- Sytem design is the art and science of putting together these resources into a harmonious whole
- Ultimately, you wish to extract the most from what you have
Simplicity
Three rules of the work:
- Out of clutter find simplicity
- From discord find harmony
- In the middle of difficulty lies opportunity
Simplicity can be an overarching philosophy, but it is too high level
Performance metrics and resource constraints
- In any system, some resources are more freely available than others
- Think about a high0end laptop connected to Internet by a DSL modem
- The constrained resource is link bandwidth
- CPU and memory are unconstrained
- We wish to maximize a set of performance metrics given a set of resource constraints
- Explicitly identifying constraints and metrics helps in designing efficient systems
- Maximize reliability (mean time between failures) for a car that costs less than 10,000 to manufacture
Real-world system design should be
- Scalable
- Modular
- Extensible
- Elegant
- Future-proof
- Rapid technological change
- Market conditions may dictate changes to design halfway through the process
- International standards, which themselves change slowly, also impose constraints
Most resources are a combination of
- time
- space
- computation
- money
- labor
- scaling
Time
Shows up in many constraints
- Deadline for task completion, time to market, mean time between failures
Metrics
- Response time: Mean time to complete a task
- Throughput: Number of taks completed per unit time
- Degree of parallelism: $Response time * Throughput$
- 20 taks completed in 10 seconds, and each task takes 3 seconds
- $3 * \frac{20}{10} = 6$
Space
Example: A limit on the memory available for a buffer to hold packets in switches and routers
We can also view bandwidth as a space constraint - A T3 link has a bandwidth of 44.768 Mbps. If we use it to carry video streams with a mean bit rate of 1.5 Mbps, we can fit at most 29 streams in this link
Scaling
A design constraint, rather than a resource constraint
- Minimizes the use of centralized elements in the design
- Yet, forces the use of complicated distributed algorithms
- Hard to measure
- But necessary for success
Bottleneck
Bottlenecks are the most constrained elements in a sytem
System performance improves by removing the bottlenecks
- But inevitably creates new bottlenecks
In a balanced system, all resources are simultaneously bottlenecked
- This is optimal, but nearly impossible to achieve
- In practice, bottlenecks move from one part of the system to another
Multiplexing and virtualization
Multiplexing: Another for sharing
Trades time and space for money
Users see an increased response time, and take up space when waiting, but the system costs less
Economies of scale make a single large resource cheaper
Examples:
- Multiplexed communication links
- Servesr in cloud computing
Another way to look at a shared resource
- Unshared virtual resource - the telephone network with time-division multiplexing
Server controls access to the shared resource
- Uses a schedule to resolve contention
- Choice of scheduling: Critical in providing quality of service guarantees
- Think about boarding a flight
Statistical multiplexing
Suppose resource has capacity C
- Shared by N identical tasks
- Each task requires capacity c
- If $N * c \le C$, then the resource is underloaded
- If at most 10% of tasks active, then $C \ge N * \frac{c}{10}$ is enough
- We used statistical knowledge of users to reduce system cost
- This is the statistical multiplexing gain
Two types of statistical multiplexing Spatial: We expect only a fraction of tasks to be simultaneously active Temporal: We expect a task to be active only part of the time - its average resource consumption is less than its peak
Batching
Batching: Trading response time for throughput
Group tasks together to amortize overhead
Only works when overhead for $N tasks < N time overhead for one task$
Also, time taken to accumulate a batch shouldn’t be too long
We’re getting reduced overhead and increased throughput, but suffering from a longer worst case response time
Randomize
Randomized algorithms may avoid maintaining states and improve performance
- Randomized quicksort
- The Monte Carlo method uses randomness for deterministic problems that are difficult to solve
But what if I have to remember and maintain some states?
- Ue soft states which expire after some time without a refresh
Layers
Use layers, but no more than 3
Traditional OSI Model
- Application Layer
- Presentation Layer
- Session Layer
- Transport Layer
- Network Layer
- Link Layer
- Physical Layer
What we need
- End-to-end layer
- Network layer
- Link layer
Review end-to-to argument
Error control: Best done in the applications Two-phase commit protocols: Do not depend on reliability FIFIO sequencing, or duplicate suppression for their correctness RISC architectures: No need to anticipate application requirements for an esoteric feature
Corollary
Use software, unless performance is not good enough
Case in point: Machine learning Implement more functions in hardware, but only when they definitely help improve the performance of the applications we run.
Hierarchies
Use hierarchies to be more scalable, but no more than 3 Examples:
- Network Time Protocol(NTP)
- Domain name system(DNS)
- Root servers
- Organization servers
- Authorized name servers
- Organization servers
- Root servers
- Certificate Authorities
- Root certificates
- Intermediate certificates
- Certificates
- Intermediate certificates
- Root certificates
- Web service
- Original servers
- Edge servers in CDNs
- Clients
- Edge servers in CDNs
- Original servers
Why do we use only 3 levels in the hierarchical design?
- Well 3 is *8scalable** enough based on real-world experiences the complexity from more levels in not necessary
Hierarchical designs are conceptually easy, but difficult to implement correctly
Ideas toward implementing hierarchies
- Cache aggressively in leaf nodes to avoid congesting the root
- Nodes in each hierarchy should depend only on their parents for proper execution
- Left-to-leaf communication is expensive to support
- Peer-to-peer vs. client-server
PTP vs. Client-Server
| PTP | Client-Server |
| Permisssionless BlockChain | Cloud Computing |
| Slow | Fast |
| PTP | Client-Server |
| Traditional Routers | Software-Defined Networking |
| Fault-tolerant | Central Point of failure |
Use the cloud as much as possible, only use peer-to-peer when necessary
Pipelines
Traditional parallelism with more processors requires breaking up a task into multiple independent subtasks
But what if the subtasks are dependent?
- One cannot start until another ends?
Pipelining parallelism increases throughput
Trad-off
Fundamentally, system design is about trade-offs
Trade-offs between more abundant resources and scarce resources at the bottleneck
Trade-offs in system design
- Multiplexing and virtualization: More time, more space consumed, but costs less
- Parallelism: More computation, less time to complete
- Batching: Trading response time for system throughput
Routing
Network Addr
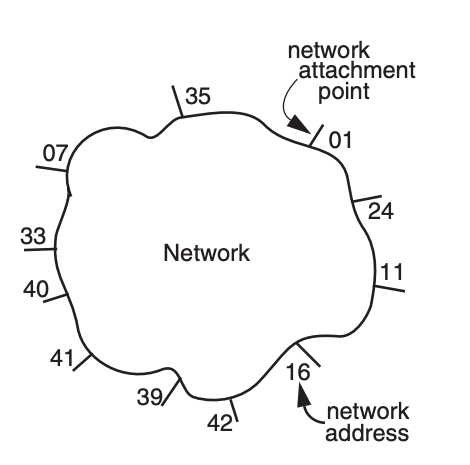
The conceptual model of a network
- A cloud bristling with network attachment points identified by numbers known as network addresses
A segment enters the network at one attachment point, known as the source
The network layer wraps the segment in a packet and carries the packet across the network to another attachment point, known as the destination, where it unwraps the original segment and delivers it to the end-to-end layer
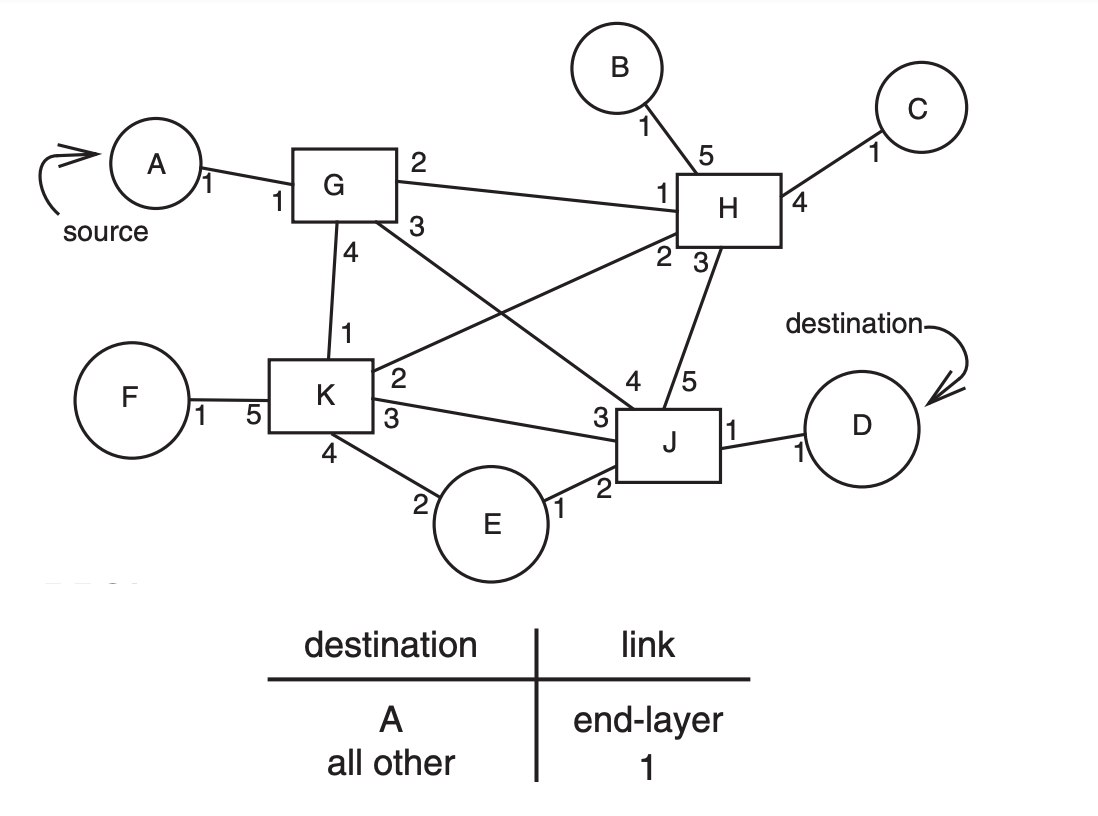
Managing the forwarding table
The primary challenge in a packet forwarding network is to set up and manager the forwarding tables
Constructing these tables requires first figuring out appropriate paths (sometimes called routes) to follow from each source to each destination routing
Setting these tables by hand is not scalable
- When links are added, removed, failed or repaired, the forwarding tables need to be recalculated
- It would be nice for forwarding tables to automatically adapt to avoid congestion
A packet forwarder that also participates in an adaptive routing algorithm is called a router
Challenges
How to construct a consistent, efficient set of forwarding tables - so that there are no loops in routes?
What defines a better routing protocol?
- A smaller number of hops to the destination
- Adaptive routing: Able to adapt to a change in topology
- Scalability: Handles a large number of destinations
Path vector algorithm
- Exchanges information of about 100,000 routers in the core of the Internet
Path Vector
Basic Idea
- Each participant maintains, in addition to its forwarding table
- A path vector, each element of which is a complete path to some destination
- Initially, the only path it knows about is the zero0length path to itself
- As the algorithm proceeds it gradually learn about other paths
- Eventually its path vector accumulates paths to every point in the network
- After each step of the algorithm it can construct a new forwarding table from its new path vector,so the forwarding table gradually becomes more and more complete
Two steps
- Advertising
- Path selection
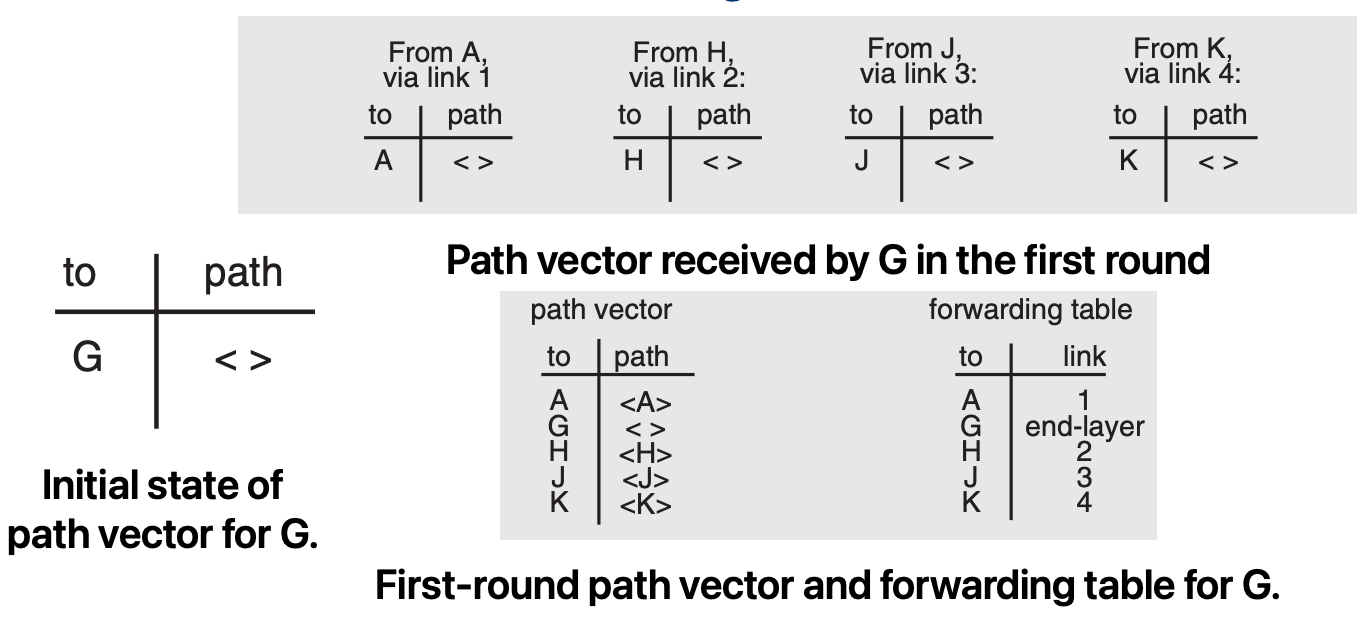
Advertising
In the advertising step, each participant sends its own network address and a copy of its path vector down every attached link to its immediate neighbours
|
 |
Path selection
G now performs the path selection step by merging the information received from its neighbours with that already in its own previous path vector
- To do this merge, G takes each received path, prepends the network address of the neighbour that supplied it, and then decides whether of not to use this path in its own path vector
- For previously unknown destination, the answer is yes
- For previously known destinations, G compares the paths that its neighbours have provided with the path it already had in its table, to see if the neighbour has a better path (smaller number of hops to the destination)
Each router discards any paths that a neighbour stops advertising - to discard links that go down
Loops
Temporary loops are still possible
- If a link has gone down, some packets may loop for a while until everyone agrees on the new forwarding table!
Solution: hop limit
- Add a field to the network-layer header containing a hop limit counter
- Decrements the hop limit counter by each router
- If a router finds it to be zero, it discards the packet
Hierarchy in routing
Two problems in our solutiosn so far
- Every attachment point must have a unique address
- It is hard to maintain a complete and accurate list of addresses already assigned when the number of addresses is large
- The path vector grows in size with the number of attachment points Solution: Introducing hierarchies
- Network addresses should be designed to have a hierarchical structure
- Both for decentralizing address assignments and for reducing the size of forwarding tables and path vectors
Assume that we have two hierarchies
- Region & Station
- We may assign to A the network address “11,75” where 11 is a region identifier and 75 is a station identifier
Key benefit
- Reduction of path vectors
- If we can adopt a policy that regions must correspond to the set of network attachment points served by a gorup of closely-connected routers
- We can use it to reduce the size of forwarding tables and path vectors
- For example, when a router for region 11 gets ready to advertise its path vectors to a router serving region 12
- It can condense all paths for region 11 into a single path
Now the problem of assigning unique addresses in a large network is also solved
- The station part of a network address needs to be unique only within its region
- A central authority assigns region identifiers
- Local authorities assign station identifiers within each region
The table lookup process is more complicated
- The forwarder needs to first extract the region component of the destination address, and look that up in its forwarding table
- Either the forwarding table contains an entry showing a link over which to send the packet to that region
- Or the forwarding table contains an entry saying that this forwarder is already in the destination region
- It is now necessary to extract the station identifier and look that up in a different part of the forwarding table
The addresses are becoming geographically dependent
Paths may no longer be the shortest possible
Congestion Control
Shared resources
Resource sharing examples in systems:
- Many virtual processors(threads) sharing a few physical processors using a thread manager
- A multilevel memory manager creates the illusion of large, fast virtual memories by combing a small and fast shared memory with large and slow storage devices
In networks, the resource that is shared is a set of communication links and the supporting packet forwarding switches
- They are geographically and administratively distributed
- Managing them is more complex
Analogy: Supermarket vs. Packet switch
Queues are started to manage the problem that packets amy arrive at a switch at a time when the outgoing link is already busy transmitting another packet
- Just like checkout lines in the supermarket Any time there is a shared resource, and the demand for that resource comes from several statistically independent sources, there will be fluctuations in the arrival of load
- Thus there will be fluctuations in the length of the queue, and the time spent waiting for service in the queue
- $Offered load > capacity of a resource$
- Overloaded
How long will overload persist?
- If the duration of overload is a comparable to service time, it is normal
- The time in a supermarket to serve one customer
- Or the time for a packet forwarding switch to handle one packet
- In this case, a queue handles short bursts of too much demand by time-averaging with adjacent periods when there is excess capacity
- If overload persists for a time significantly longer than the ervice time, there begins to develop a risk that the system will fail
- To meet some specification, such as maximum delay
- When this occurs, the resource is said to be congested
- If congestion is chronic, the length of the queue will grow without bound
The stability of offered load The stability of offered load is another factor in the frequency and duration of congestion
- When the load on a resource is aggregated from a large number of statistically independent small sources
- Averaging can reduce the frequency and duration of load peaks
- When the load comes from a small number of large sources, even if the sources are independent
- The probability that they all demand service at about the same time can be high enough
- That congestion can be frequent or long-lasting
Congestion Collapse
Competition for resource may lead to waster of resource
Example -Customers who are tired of waiting may just walk out, leaving filled shopping carts behind
- Someone has to put the goods from abandoned carts back to the shelves
- One of two of the checkout clerks leave their registers to do so
- The rate of sales being rung up drops while they are away
- The queues at the remaining registers grow longer
- Causing more people to abandon their carts
- Eventually, the clerks will be doing nothing but restocking
Once temporary congestion induces a collapse, even if the offered load drops back to a level that the resource can handle, the already induced waster rate can continue to exceed the capacity of the resource
- This will cause it to continue to waster the resource, remain congested indefinitely
Resource management
Primary goal of resource management
- Avoid congestion collapse
- By increasing the capacity of the resource
- By reducing the offered load There is a need to move quickly to a state in which the load is less than the capacity of the resource
- But when offered load is reduced, the amount reduced does not really go away
- It is just deferred to a later time at the source
- The source is still averaging periods of overload with periods of excess capacity, but over a longer period of time
How to increase capacity or reduce load?
- It is necessary to provide feedback to one or more congestion points
- An entity that determines
- The amount of resource that is available
- The load being offered
- An entity that determines
- A congestion control system is fundamentally a feedback system
- A delay in the feedback path can lead to oscillations in load
In a supermarket, a store manager can be used to watch the queues at the checkout lines
- Whenever there are more than two or three customers in any line
- The manager calls for staff elsewhere in the store
- To drop what they are doing
- Temporarily take stations as checkout clerks
- The manager calls for staff elsewhere in the store
- This practically increases capacity
When you call customer service, you may hear an automatic response message
- “The estimated wait time is 30 minutes”
- This may lead some callers to hang up and try again at a different time
- This practically decreases load Both may lead to oscillations
Shared resources in a computer network
- Communication links
- The processing and buffering capacity of the packet forwarding switches
Main Challenges
Part 1
There is more than one resource
- Even a small number of resources can be used up in a large number of different ways, which is complex to keep track of
- There can be dynamic interactions among different resources as one nears capacity it may push back on another
- Which may push back on yet another
- Which may push back on the first one
It is easy to induce congestion collapse
- As queues for a particular communication link grow, delays grow
- When queuing delays become too long, the timers of higher layer protocols begin to expire and trigger retransmissions of the delayed packets
- The retransmitted packets join the long queues, and waster capacity
As memory gets cheaper, the idea is tempting - but it doesn’t work
- Suppose memory is so cheap that a packet forwarder can be equipped with an infinite buffer size, which can absort an unlimited amount of overload
- But as more buffers are used, the queuing delay grows
- At some point the queuing delay exceeds the timeouts of end-to-end protocols
- Packets are retransmitted
- The offered load is now larger, so the queue grows even longer
- It becomes self-sustaining and the queue grows even longer
- The infinite buffer size does not solve the problem, it makes it worse
Part2
There are limited options to expand capacity
- Capacity is determined by physical facilities (wireless spectrum)
- One can try sending some queued packets via an alternate path
- But these strategies are too complex to work well, as one needs to know the instantaneous state of the queues throughout the network
- Reducing the offered load (the demand) is the only realistic way
- One can try sending some queued packets via an alternate path
Part 3
The options to reduce load are awkward
- The control point for the offered load is too far away
- Feedback path to that point may be long
- By the time the feedback signal get there
- The sender may have stopped sending already
- The congestion may have disappeared
- The feedback may be lost
- Feedback path to that point may be long
- The control point must be capable of reducing its offered load
- Video streaming protocols are not able to do this
- The control point must be willing to cooperate
- The packet forwarder in the network layer may be under a different administration than the control point in the end-to-
- The control point is more intersted in keeping its offered load equal to its intended load
- In the hope of capturing more of the capacity in the face of competition
Address challenges
OverProvisioning
Basic idea: Configure each link of the network to have 125% or 200% as much capacity as the offered load at the busiest minute of the day
- Works best on interior links of a large network, where no individual client represents more than a tiny fraction of the load
- Average load offered by a large number of statistically independent sources is relatively stable
Problem
- Odd event can disrupt statistical independence
- OverProvisioning on one link will move congestion to another
- At the edge, statistical averaging stops working flash crowd
- User usage patterns may adapt to the traditional capacity
Pricing in a market: The invisible hand Since network resources are just another commodity with limited availability, it should be possible to use pricing as a congestion control mechanism
- If demand for a resource temporarily exceeds its capacity, clients will bid up the price
- The increased price will cause some clients to defer their use of the resource until a time when it is cheaper, thereby reducing offered load
- Consider hydro charge in different time slot
- It will also induce additional suppliers to provide more capacity
Challenges
- How do we make it work on the short time scales of congestion?
- Clients need a way to predict the costs in the sort term, too
- there has to be a minimal barrier of entry by alternate suppliers
Cross-layer feedback
The packet forwarder that notices congestion provides feedback to one or more end-to-end layer sources
The end-to-end source responds by reducing its offered load
The best solution:
- The packet forwarder simply discards the packet
Which packet to discard? The choice is not obvious
- The simplest strategy, tail drop, limits the size of the queue, and any packet that arrives when the queue is full gets discarded
- A better technique, called random drop, chooses a victim from the queue at random
- The sources that are contributing the most to congestion are the most likely to received the feedback
- Another refinement, called early drop
- Begins dropping packets before the queue is completely full
- In the hope of altering the source sooner
- The goal of early drop
- Start reducing the offered load as soon as the possibility of congestion is detected, rather than waiting till congestion is confirmed
- Avoidance rather than recovery
- Begins dropping packets before the queue is completely full
- Random drop + Early drop: Random early detection (RED)
What should the end-to-end protocol do?
One idea: Just retransmit the lost packet, and continue to send more data as rapidly as its application supplies it
- This way, it may discover that by sending packets at the greatest rate it can sustain, it will push more data through the congested packet fowrader
- Problem: If this is the standard mode of operation of all end hosts, congestion will set in and all will suffer
- “The tragedy of the commons”
Two things that the end-to-end protocol can do
- Be careful about the use of timers
- Involves setting the timer’s value
- Pace the rate at which it sends data
- Automatic rate adaptation
- Involves managing the flow control window
- Both require having an estimate of the round-trip time between the two end of the protocol
The retransmit timer
With congestion, an expired timer may imply that either a queue in the network has grown too long, or a packet forwarder has intentionally discarded the packet
We need to reduce the rate of retransmissions
- Idea: RTT estimates
- Develop an estimate of the RTT by directly measuring it
- Longer queuing delays will increase the observed RTT
- These observations will increase the rtt estimate used for setting future retransmit timers
When a timer does expire, exponential backoff for the timer interval should be used for retransmitting the same packet
- Effectively avoids contributing to congestion collapse
Automatic rate adaptation The flow control windows and the receiver’s buffer should both be at least as large as the bottleneck data rate multiplied by the RTT - the BDP(Bandwidth-delay produce)
But if it is larger, it will result in more packets piling up in the queue of the bottleneck link
We need to ensure that the flow control window is no larger than necessary
TCP design
In the original TCP design, the only form of acknowledgement to the sender was “I have received all the bytes up to X”
- But not in the form of “I am missing bytes Y through Z”
The consequences
- When a timer expired due to a lost packet, as soon as the sender retransmitted that packet, the timer of the next packet, expired, causing its retransmission
- This will repeat until the next acknowledgment returns, a full round trip later
- On long-delay routers, the flow control window may be large
- Each discarded packet will trigger retransmission of a window full of packets
- Congestion Collapse
Solution By the time this effect was noticed, TCp was already widely deployed, so changes to TCP were severely constrained
- They have to be backward compatible
The result
- One expired timer leads to slow start
- Send just one packet, and wiat for its acknowledgement
- For each acknowledged packet, add one to the window size
- In each RTT, the number of packets that the sender sends doubles
- This repeats till
- The receiver’s window size has been reached
- The network is not the bottleneck
- A packet loss has been detected
- The receiver’s window size has been reached
Duplicate acknowledgment
The receiving TCP implementation is modified slightly
- Whenever it receives an out-of-order packet, it sends back a duplicate of its latest acknowledgment 0 Such a duplicate can be interpreted by the sender as a NAK
The sender then operates in an equilibrium mode
- Upon duplicate acknowledgment
- The sender retransmits just the first unacknowledged packet and also drops its windows size to some fixed fraction of its previous size
- After this it proves gently for more capacity by doing
- Additive increase: Whenever all the packets in a RTT are successfully acknowledged, the sender increases the window size by 1
- Multiplicative decrease: Whenever a duplicate acknowledgment arrives again, the sender decreases the size of the window again, by a fixed fraction
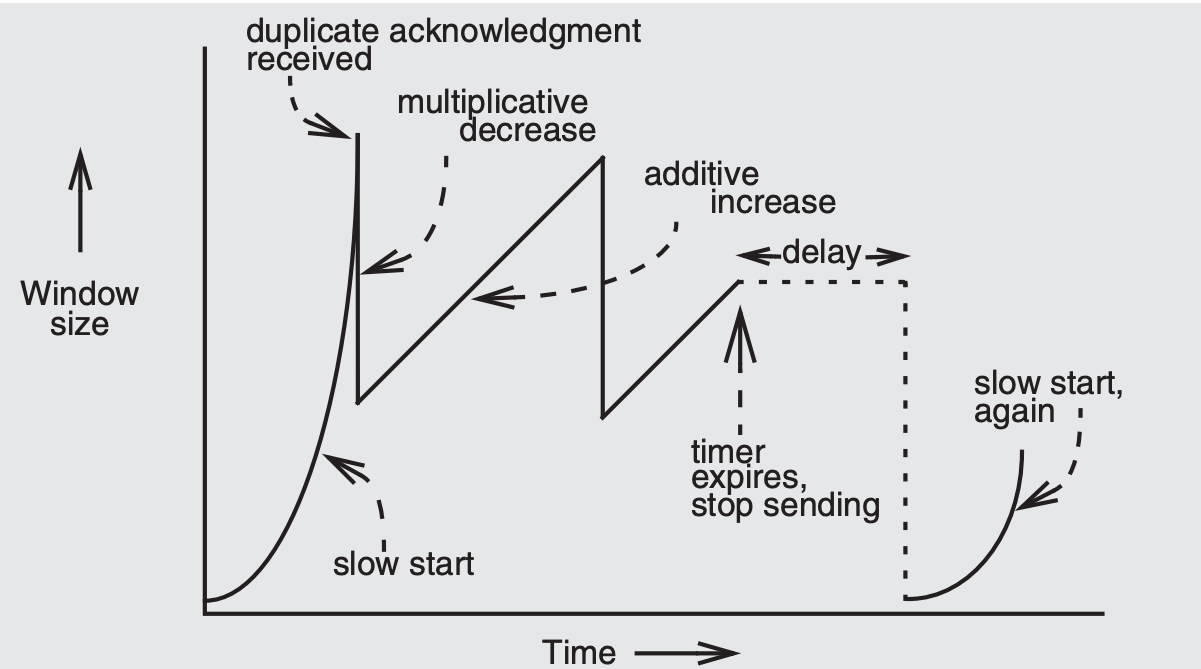
Real-world meaurement studie have shown
- By probing 5000 popular web servesr, researchers have found that only 15-20% uses AIMD TCP
What about the other 80%?
- It turns out that web servers, which are what define the Internet, use a wide variety of different TCP protocols, each with its own congestion control protocol
Problem of AIMD
As Internet evolves, the number of long latency and high bandwidth networks grows
- The Bandwidth and Delay Product(BDP)
- The total number of packets in flight, determined by the flow control window ize on the sender, must fully utilize the bandwidth
- Standard AIMD TCP increases its congestion window size too slowly in high BDP environments
- Example: Bandwidth 10Gbps, RTT 100ms, Packet size 1250 bytes, takes 10,0000 seconds to fully utilize
- $10 * 1000000 / (1250 * 8) / (0.1) = 100000$
- Example: Bandwidth 10Gbps, RTT 100ms, Packet size 1250 bytes, takes 10,0000 seconds to fully utilize
New congestion control design objectives
- Highly scalable to high BDP environments
- Very slow (gentle) window increase at the saturation point
- Fair to AIMD TCP flows
- Backward compatibility
Binary Increase Congestion (BIC)
After a packet loss, reduces its window by a multiplicative factor of $\beta$, the deafult is 0.2 -The window size just before reduction is set to $W_{max}$ and after reduction $W_{min}$ -In the next step, it finds the midpoint using theses two sizes and jump there - Binary Search - But if midpoint is very far from $W_{min}$ a constant value called $S_{max}$ is used
- If no loss, $W_{min}$ is set to the new window size
- The process continues until the increment is less than a constant value of $S_{min}$
- Then it is set to the maximum window
- If not loss, new maximum must be found and it enters a “max probing” phase
- Window growth function is exactly symmetric to the previous part
BIC works very well in production, but in low speed or short RTT networks it is too aggressive for TCP
Different phases like binary search increase, max probing, $S_{max}$ and $S_{min}$, make its implementation not very efficient
A new congestion control protocol is required to solve these problems, while keeping its advantages of stability and scalability
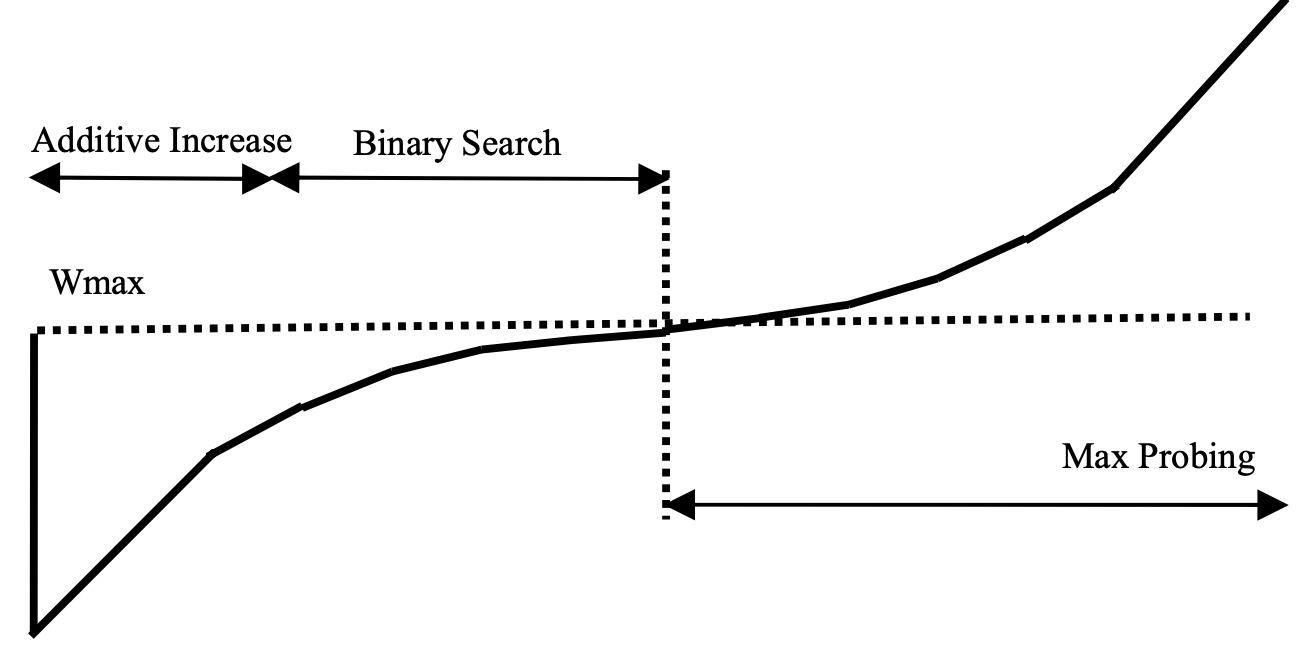
CUBIC
As the name suggests, it uses cubic function for window growth
- It uses time instead or RTT to increase the window size
- It contains a “TCP mode” to behave the same as AIMD TCP when RTTs are short
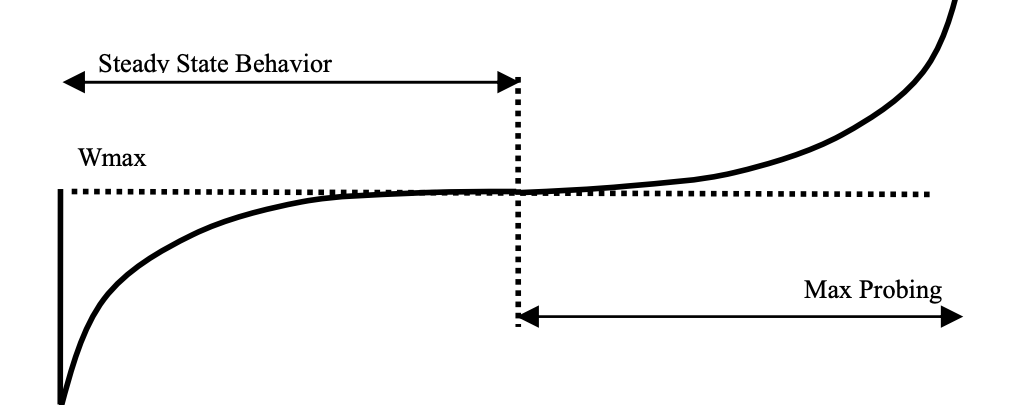
After a packet loss, reduces its window by a multiplicative factor of $\beta$, the default is 0.2
- The window size just before reduction is set to $W_{max}$
- After it enters intro congestion avoidance, it starts to increase the window using a cubic function
- The plateau of cubic function i set to $W_{max}$
- Size of the window grows in concave mode to reach $W_{max}$ then it enters the convex part
BBR
Congestion-Based Congestion Control
BBR algorithm differs from loss-based congestion control in that it pays relatively little attention to packet loss
- Instead, it focuses on the actual bottleneck bandwidth
- In the “startup” state, it behaves like most traditional congestion-control algorithms
- Quickly ramps up the sending rate in an attempt to measure the bottleneck bandwidth
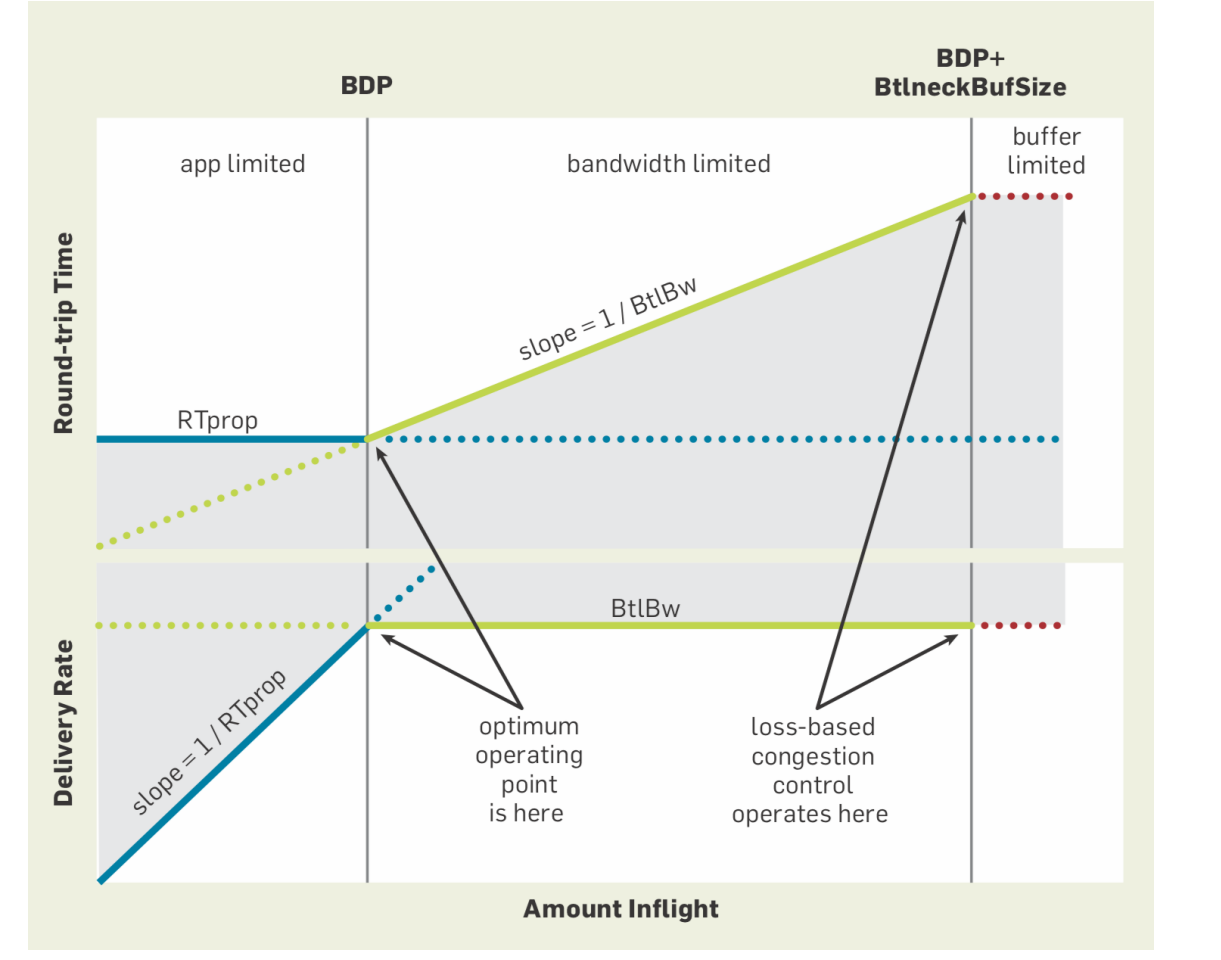
Stop Ramping Up Early -Instead of continuing to ramp up until it experiences a dropped packet, it watches the bottleneck bandwidth measured for the last several round-trip times
-Once the bottleneck bandwidth stops rising, BBR concludes that it has found the effective bandwidth of the connection and can stop ramping up - This has a good chance of happening well before packet loss would begin
Drain State
- In measuring the bottleneck bandwidth, BBR probably transmitted packets at a higher rate for a while
- Some of them will be sitting in queues waiting to be delivered
- To drain those packets out of the buffers where they languish, BBR will go into a drain state
- During which it will transmit below the measured bandwidth
- Until it has made up for the excess packets sent before
Steady State
- Once the drain phase is done
- BBR goes into the steady-state mode
- Where it paces outgoing packets
- So that the packets in flight is more-or-less the calculated BDP
- BBR goes into the steady-state mode
- Scale the rate up by 25% periodically to probe for an increase in effective bandwidth